

Billet rédigé par Reynald Stephan, Benjamin Brudo, Romain Brochot, Damien Prudent, Etienne Perrier, Matthieu Rollin, Julien Berthoux et Stéphane Prouvez. Equipe ECM Atol CD.
Cette année était une année un peu particulière pour la DevCon. En raison du contexte sanitaire actuel, le rendez-vous international de la communauté Alfresco qui devait initialement se tenir à Londres, n’a pu avoir lieu en présentiel. C’est donc en mode “virtuel” que 6 collaborateurs d’Atol Conseils et Développements ont suivi avec attention la dizaine de présentations dispensées sur deux journées par les experts Alfresco.
Nous vous proposons une synthèse des différentes sessions sur les nouveautés et axes de développement de la plateforme Alfresco.
# Le futur de la communauté Alfresco (Alfresco Update / Alfresco Community; Road Ahead / Keynote)
https://event.on24.com/wcc/r/2503468/ABC11D6C77CCD6C7851C41302619E38A
La DevCon a commencé par une explication de Jay Bhatt (CEO Alfresco) sur le rachat d’Alfresco par Hyland (n’informant pas à ce jour des impacts et possibles opportunités pour Alfresco et sa communauté. Affaire à suivre ….) Suite à cette explication, John Newton (Cofondateur d’Alfresco) s’est lancé dans une keynote sur les origines des mots « transformation », « processus » et « cas » (avec beaucoup de références à la langue française, et notamment Jeanne d’Arc). L’idée étant de présenter les différents modèles de transformation digitale, et montrer dans quelle mesure Alfresco est la plateforme idéale pour l’application de ces idées.
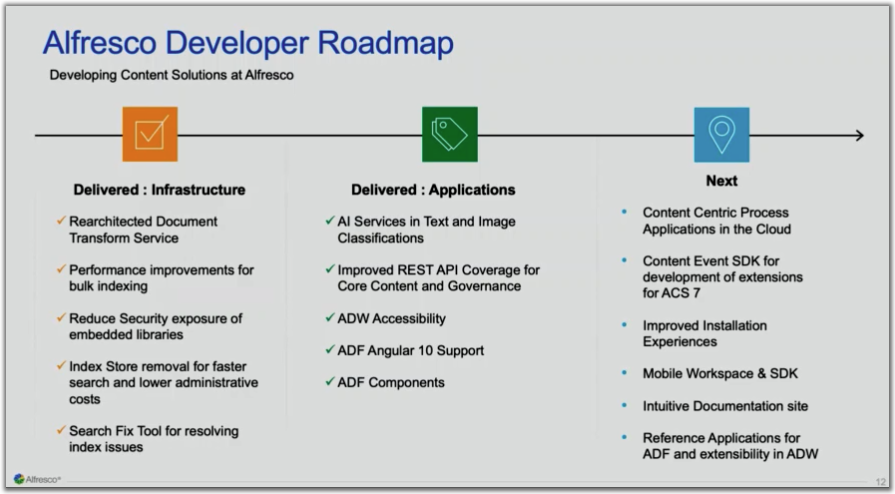
Au cours de l’année, Alfresco a réalisé un certain nombre d’enquêtes auprès de ses clients sur les extensions construites avec les partenaires et les fonctionnalités que les clients aimeraient voir dans le produit. Mo Ladha (VP Product Management) a présenté les résultats de ces enquêtes et leur impact sur la feuille de route.
# Tirer le meilleur parti de l’Audit Alfresco
https://event.on24.com/wcc/r/2585061/9F691C1ACF9F3B12C2136EABF2E86CD7
Pourquoi le mécanisme d’audit d’Alfresco est puissant ? Ce mécanisme capture ce qui se passe dans la partie Repository d’Alfresco. Tout ce qui apparaît donc dans l’audit s’est déroulé dans cette brique d’Alfresco.
Par exemple, si une transaction échoue, l’audit créera une entrée et indiquera pourquoi elle a échoué.
Également, si le mécanisme d’audit ne suffit pas, on peut l’étendre pour gérer d’autres informations.
Enfin, l’audit peut aussi être séparé par applications suivant les cas d’utilisations.
D’autres alternatives existent pour surveiller l’activité du côté du repository Alfresco mais elles ne seront pas forcément appropriées à vos cas d’utilisation. On peut citer :
- les différents journaux mais ils sont plutôt destinés à debugger les applications et on ne peut pas les requêter
- les transactions mais qui sont plutôt utilisées pour des recherches sur l’indexation et ne reflètent que l’état courant du repository
- les captures d’événements et les files d’attente qui sont plutôt utilisées pour la gestion des transformations.
Si l’audit semble puissant, il faudra faire attention aux pièges qui pourront se présenter.
Par l’exemple, l’approche “Collecter et oublier” qui peut s’avérer être, je cite, “un vrai désastre” :
- Les tables vont grossir à l’infini suivant l’activité, le nombre d’événements surveillés car il n’y a pas de purge automatique et les performances seront impactées
- Les informations seront difficiles à requêter, ce n’est pas destiné à être un entrepôt de données. Dans certains cas, on ne pourra filtrer que sur des intervalles de temps ou intervalles d’identifiants.
- Les entrées de l’audit ne racontent pas tout car le repository ne sera qu’une partie du système d’informations ou bien parce que des workflows sont associés aux documents.
Ce qui sera à considérer concernant l’audit Alfresco sera principalement :
- Comment les données seront utilisées ?
- Qui sont les clients ?
- A quel point les données doivent-elles être récentes ?
- Quelles sont les autres données qui nous raconteront l’histoire complète ?
- Y a-t-il des prérequis pour la rétention de données de l’audit ?
Il n’y a donc pas de recette miracle pour exploiter l’audit Alfresco et son utilisation doit faire partie d’une stratégie.
Le conseil principal sera d’utiliser l’audit pour des rapports simples sur l’activité récente du repository et d’exporter le reste dans un ETL pour les autres besoins.
Pour ce faire, vous devrez utiliser des API fournies par Alfresco.
Il existe l’API Java “Audit Service” qui permet de faire des requêtes simples de récupération (auditQuery) ou de nettoyage (deleteAudiEntries).
/!\ Attention cette API n’est pas officielle et ne fait pas partie de l’API publique Alfresco.
Il est préférable donc de privilégier l’API REST qui permet de faire les mêmes choses mais nativement et de façon plus élaborée.
- GET avec filtres de type skipCount, maxItems, include et where
- DELETE : par intervalles de date
De plus, toutes les fonctionnalités sont documentées ici :
https://api-explorer.alfresco.com/api-explorer/#/audit
Pour compléter ce qui a été dit précédemment, il faut prévoir une stratégie spécifique pour cette gestion des données d’audit et surtout prévoir une purge régulière. Il est nécessaire d’utiliser l’API Java pour pousser les données mais recommandé d’utiliser la Rest API pour les récupérer, cette dernière étant bien plus flexible. Dans cette stratégie, prévoir une extraction sous forme d’archive de l’historique avant de faire une purge.
Une démo développée par Rich McKnight est disponible ici :
https://github.com/rmknightstar/decvon2020
# Déployer ACS avec Kubernetes : du développement jusqu’à la production
https://event.on24.com/wcc/r/2585061/9F691C1ACF9F3B12C2136EABF2E86CD7
Il existe différents moyens pour déployer Alfresco sur son système d’information. L’installation manuelle, l’installation automatisée avec Ansible (également en cours de réalisation chez Alfresco) et enfin avec Docker. Alfresco fournit toutes ses applications sous forme de container Docker.
En environnement de développement il est possible d’utiliser Docker compose pour mettre en place rapidement ses containers. Mais Docker compose manque de fonctionnalités et s’avère donc peu recommandé pour les environnements de production (particulièrement en cas de cluster).
 Kubernetes est un orchestrateur de services conteneurisés qui peut être utilisé pour réaliser le suivi et la configuration des containers. L’intérêt d’utiliser Kubernetes est de pouvoir gérer rapidement l’état d’un cluster déployé. En effet, avec cet orchestrateur il est possible de choisir le nombre d’instances à démarrer, l’allocation des ressources pour la volumétrie et tous les autres paramètres nécessaires à la maintenabilité des systèmes dans l’état souhaité.
Kubernetes est un orchestrateur de services conteneurisés qui peut être utilisé pour réaliser le suivi et la configuration des containers. L’intérêt d’utiliser Kubernetes est de pouvoir gérer rapidement l’état d’un cluster déployé. En effet, avec cet orchestrateur il est possible de choisir le nombre d’instances à démarrer, l’allocation des ressources pour la volumétrie et tous les autres paramètres nécessaires à la maintenabilité des systèmes dans l’état souhaité.
Il peut gérer les aspects suivants :
- Load Balancing : Il n’a jamais été aussi facile de monter un cluster Alfresco !
- Stockage
- Sauvegarde / Restauration
- Auto bin packing : gestion automatique des ressources
- Monitoring et “auto-healing” : Kubernetes est capable de surveiller les containers et de réaliser des actions en cas de problème (redémarrage d’un container en erreur, création d’un nouveau container pour supporter la charge, etc..)
- Fichiers de configuration et mot de passe
Kubernetes se décompose en deux parties :
- Kubernetes Master qui est responsable de la gestion des différentes ressources des noeuds.
- Kubernetes Node qui contiennent ce que l’on appelle des pods. Ces derniers sont contrôlés par Kubernetes. Un pod peut contenir différentes applications conteneurisées ainsi que différents volumes. En d’autres termes, les pod hébergent une ou plusieurs applications avec les ressources suivantes :
- Volumes de stockage partagés
- Mise en réseau, ports exposés
- Images choisies
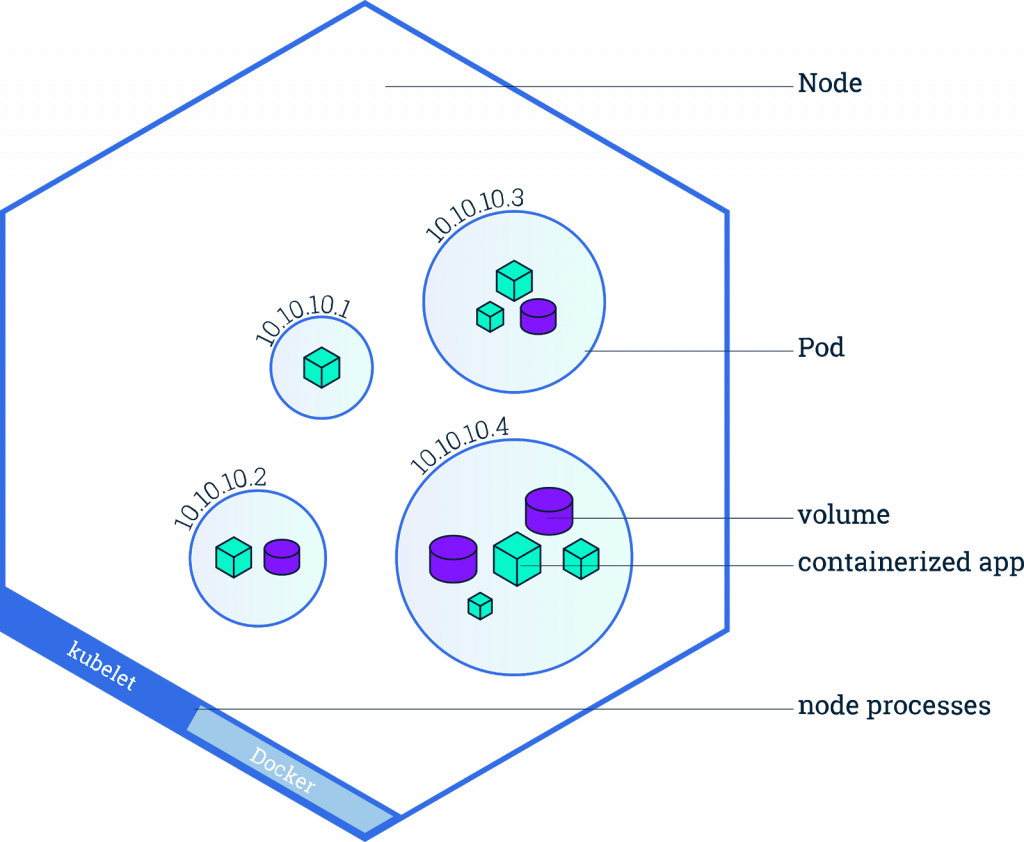
(extrait de https://kubernetes.io/docs/tutorials/kubernetes-basics/explore/explore-intro/)
La configuration de Kubernetes se fait grâce à des fichiers yaml. Quand le nombre d’applications et d’environnements reste raisonnable, la configuration est simple. Mais dans le cas contraire, on se retrouve avec beaucoup de fichiers plus ou moins semblables.
Mais il y a une solution : Helm.
 Helm est un package manager (LE package manager recommandé par Kubernetes). A ce titre son utilisation est semblable à des packages manager plus connus comme APT ou YUM.
Helm est un package manager (LE package manager recommandé par Kubernetes). A ce titre son utilisation est semblable à des packages manager plus connus comme APT ou YUM.
Il va permettre d’utiliser des templates et des dépendances pour éviter la duplication de fichiers de configuration.
L’idée est d’avoir un magasin d’applications pré-configurées déployable en une seule ligne de commande.
Plus précisément : Helm est le client qui permet de récupérer les charts pour les appliquer sur un cluster Kubernetes. Les charts représentent une collection de fichiers Yaml décrivant les ressources, un chart contient toutes les informations nécessaires à la création d’une instance Kubernetes.
# Produire des AMPs de façon pérenne
https://event.on24.com/wcc/r/2585066/BBBFB612E88B060EB9DB38A43EBF0C96
Cette session concernant les AMPs (Alfresco Module Package – livrable contenant un module Alfresco) a mis en avant plusieurs recommandations concernant le développement des modules.
Ces AMPs sont en fait vus comme des points d’extension d’Alfresco.
Avant d’en venir aux recommandations, voici quelques rappels concernant le fonctionnement d’Alfresco et des modules.
Le repository sous forme de WAR est délivré sur un serveur d’applications, Tomcat. Au démarrage, cette archive est éclatée et un classpath est construit et est isolé des autres applications tournant sur le même serveur et également de Tomcat.
Ensuite, l’application Alfresco est basée sur le Framework Spring (pattern d’inversion de contrôle). Cette inversion de contrôle est assurée de deux façons différentes : la recherche de dépendances et l’injection de dépendances.
Spring va nous permettre de définir des composants informatiques appelés beans. Ces derniers sont déclarés sous forme de fichiers XML.
Dans Alfresco, nous pourrons donc déclarer plusieurs points d’extension :
- des webscripts (“APIs”)
- des policies / behaviours (traitements déclenchés sous forme d’événements sur les noeuds)
- des interfaces de fournisseurs de service
Ces développements seront ensuite déployés sous forme de JAR en utilisant l’outil Module Management Tool. Les éléments du module seront donc ajoutés au classpath du repository Alfresco cité précédemment.
Concernant le déploiement au format .amp (ZIP), la mécanique est légèrement différente. Les ressources (jar, properties, css, …) sont copiées dans l’application Alfresco grâce à des mappings, ce qui peut impliquer des problèmes.
Voici donc quelques recommandations concernant les AMPs :
- ne jamais écraser de fichiers avec un AMP car les noms de fichiers et leur contenu peuvent varier entre les versions d’Alfresco
- éviter les conflits de noms de classe, on ne peut pas avoir deux versions différentes de la même librairie : attention donc aux dépendances transitives en utilisant Maven
- ne pas re-déclarer un bean Spring implémenté par Alfresco. Exemple : NodeService
- ne pas utiliser une API Alfresco non publique
- ne pas inclure une librairie tierce gérée par le repository. On peut citer l’exemple d’une montée de version ACS où des librairies peuvent potentiellement être mises à jour. Exemple : 71 librairies ont été mises à jour lors du passage de la version 6.0.1 à 6.0.2
Pour faciliter la vie des développeurs, Alfresco va donc mettre à disposition l’outil Alfresco Extension Inspector permettant de détecter automatiquement ce type de transgressions, notamment :
- Conflits de fichiers
- Conflits dans le classpath
- Conflits de nom de bean
- Utilisation d’une API Alfresco non publique
- Utilisation de librairies tierces gérées par le repository
Ainsi, il est envisageable d’utiliser cet outil pour analyser des projets et ainsi éviter des écueils lors de montées de version d’Alfresco. Cet outil est pour l’instant destiné à être utilisé manuellement car la sortie produite demande une intervention humaine pour être exploitée. Il sera disponible pour les versions Enterprise d’Alfresco 5.2+ en début d’année prochaine.

Enfin, voici quelques suggestions d’implémentations pour s’abstraire de tous ces problèmes :
- Pour les transformations, passer par les T-Engines
- Pour la logique métier, développer un service séparé, en dehors du repository
- Pour les behaviours, utiliser les Events ; ils devraient être plus nombreux avec ACS 7
# La sécurité avant tout
https://event.on24.com/wcc/r/2585067/C401F299DAEE1E5FBD1E85D962D27A50
Pour commencer, voici quelques mythes autour de la sécurité dans le développement informatique (faux bien évidemment) :
- La sécurité est juste une tâche comme les autres
- La sécurité est juste une fonctionnalité
- On doit être un expert en sécurité pour pouvoir s’en occuper
- On a une équipe dédiée à la sécurité donc tout va bien
- Ce projet est une petite cible, les hackers ne vont pas s’y intéresser
- On doit tout reprendre l’existant pour sécuriser
- La sécurité peut attendre la fin du projet
La sécurité doit être prise en compte lors du développement à tous les niveaux et par tous les acteurs. Voici quelques idées pour améliorer son intégration :
- Construire une culture de la sécurité via
- la formation
- les checklists
- planifier la sécurité lors des projets
- être préparé pour réagir à un incident
- avoir des bacs à sable pour faire des tests
- Avoir un code de conduite pour les développeurs
- ne livrer que des logiciels de qualité
- avoir une productivité stable
- pouvoir modifier son code sans trop d’effort
- amélioration continue du code
- qualité extrême
- etc.
- La sécurité est une problématique transversale et doit être prise en compte comme telle
- Mettre en place de l’intégration continue avec
- analyse des dépendances
- utilisation d’outils approuvés uniquement
- analyse statique du code (en rapport avec la sécurité)
- analyse dynamique du code
- tests d’intrusion
- suivi des nouvelles failles
- Mettre en place du monitoring et analyser les retours
- gestion des logs sûre
- récupération, archivage et accès aux logs
- définir des indicateurs et des rapports de conformités
- déclencher des alertes
- Définir un processus de gestion des incidents (au travers de checklists par exemple)
- Prendre en compte les modèles de responsabilités partagées des hébergeurs Cloud (AWS, Azure, etc.) le cas échéant
# Vous n’avez pas Docker ? Automatisation de l’installation et de la configuration avec Ansible
https://event.on24.com/wcc/r/2585067/C401F299DAEE1E5FBD1E85D962D27A50
Il y a quelques mois, nous avions présenté dans notre blog l’utilisation d’Ansible (https://blog.atolcd.com/ansible/). Alfresco travaille également sur un déploiement de leur solution avec Ansible (https://github.com/jpotts/ansible-alfresco) (*).
En effet, même si le déploiement par Docker (et Kubernetes) est privilégié par Alfresco, il ne peut pas être utilisé par tout le monde : l’utilisation de Kubernetes nécessite une architecture spécifique et des compétences en interne qui ne sont pas forcément maîtrisées ou voulues.
 C’est ici qu’Ansible intervient ! Pas besoin de modification d’architecture ou de compétences supplémentaires. Mais le système d’automatisation va permettre de réaliser les installations et les updates plus sereinement.
C’est ici qu’Ansible intervient ! Pas besoin de modification d’architecture ou de compétences supplémentaires. Mais le système d’automatisation va permettre de réaliser les installations et les updates plus sereinement.
Principaux bénéfices par rapport à une installation “à la main” :
- Gain de temps : le script, une fois mis en place, va pouvoir installer les applications nécessaires sur tous les serveurs en quelques minutes.
Et plus on a de serveurs (cluster alfresco, plusieurs solr, etc..), plus le gain de temps sera important !
- Moins d’erreurs “humaines” : un fichier de configuration à modifier sur X serveurs ? Ansible le transmet sur chaque serveur ! Pas d’oubli possible !
- Scalability : Ajout d’un nouveau Alfresco dans le cluster ? Ajout d’un nouveau Solr ? Ansible réalise l’installation et la configuration sur le nouveau serveur/machine virtuelle.
* Notons toutefois, qu’Alfresco fournit ici l’ensemble des playbooks pour l’installation standard d’un Alfresco. Son intégration au sein du système d’information doit être effectuée dans un second temps sur un playbook à part entière et particulier à chaque infrastructure.
Laisser un commentaire