Dans le cadre d’un projet client, l’ANFR, nous avons mis en œuvre des fonctionnalités de recherche de similarités sonores. L’idée était de limiter les doublons liés aux saisies des noms de famille par des opérateurs lors de réclamations créées à partir d’appels téléphoniques. En effet, il arrive régulièrement que les réclamants appellent plusieurs fois et la saisie des noms de famille est souvent problématique.

# Cas d’utilisation
M. Dupont appelle le service de l’ANFR pour signaler une anomalie. L’opérateur téléphonique enregistre la nouvelle fiche. Parmi les informations qu’il renseigne, on retrouve plusieurs critères sur lesquels s’appuie le rapprochement :
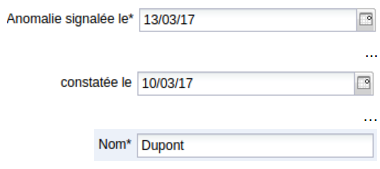
Avant la validation de la fiche, un assistant de l’application suggère une anomalie qu’il a détectée :

En effet, la veille, M. Dupond a appelé pour signaler une anomalie dans la même zone géographique. Après vérification, l’opérateur téléphonique crée un lien entre les deux fiches. Les données sont immédiatement valorisées si bien que les croisements ultérieurs sont facilités.
# Algorithmes employés
Plusieurs d’algorithmes intéressants existent. Nous nous sommes appuyés sur deux algorithmes que nous n’avons pas inventés :
- Soundex fr est version francisée de Soundex. Ce dernier est un algorithme de calcul d’une signature phonétique d’une chaîne de caractères (deux chaînes proches ont la même signature).
- Jaro-Winkler permet de calculer une distance entre deux chaînes de caractères. La résultat est comprise entre 0 (les chaînes sont très éloignées, i.e. complètement différentes) et 1 (elles sont similaires)
# Implémentation
Dans un souci de performances, nous réalisons les calculs au plus près des données car le volumétrie est importante. Nous avons choisi d’implémenter des fonctions PostgreSQL adéquates sur lesquelles s’appuient les prédicats JPA utilisés par l’application serveur Java lors de la consommation de web services.
# Côté PostgreSQL
L’implémentation de la version francisée de l’algorithme soundex est inspirée de la version soundex_fr de Damien Griessinger. Celle de Jaro Winkler a été réalisée pour l’occasion.
Au niveau de la base de données, on retrouve les deux fonctions suivantes :
|
1 2 3 |
FUNCTION util.soundex_fr(text) RETURNS text FUNCTION util.jaro_winkler(str1_in text, str2_in text) RETURNS double precision |
Exemples de calcul d’empreintes Soundex fr :
|
1 2 3 4 5 |
select util.soundex_fr('dupont'), util.soundex_fr('dupond') "D153";"D153” select util.soundex_fr('vagner') as vagner "V756" |
Exemples de comparaison Jaro-Wrinkler :
|
1 2 3 4 5 6 7 8 |
select util.jaro_winkler('dupont', 'dupond') 0.888888888888889 select util.jaro_winkler('dupont', 'drupal') 0.666666666666667 select util.jaro_winkler('vagner', 'wagnerr') 0.849206349206349 |
Dans le projet en question, nous souhaitons récupérer les réclamations dont le nom du signalant a la même signature phonétique Soundex fr que ”Dupont” ou dont la distance Jaro-Winkler est supérieure ou égale à 0.75. La requête SQL ressemble au modèle suivant :
|
1 2 3 4 5 6 7 8 |
select [...] from reclamation r join signalant s on (r.signalant=s.id) where [...] and ( util.soundex_fr(c.nom) = util.soundex_fr('dupont') or util.jaro_winkler(c.nom, 'dupont') >= 0.75 ) |
Remarque : pour optimiser les recherches en cas de volumétrie importante et d’utilisation régulière, il est préférable d’utiliser des index basés sur les signatures soundex_fr.
# Côté Java
Je ne m’attarde pas sur les détails dans ce paragraphe. Notons que nous utilisons JPA/Hibernate pour accéder aux données.
Dans un premier temps, nous enrichissons le dialecte Hibernate utilisé, qui dérive de org.hibernate.dialect.Dialect :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
import java.sql.Types; import org.hibernate.dialect.function.StandardSQLFunction; import org.hibernate.spatial.dialect.postgis.PostgisDialect; import org.hibernate.type.StandardBasicTypes; public class AnfrPostgisDialect extends PostgisDialect { public AnfrPostgisDialect() { [...] // Soundex et Jaro Winkler registerFunction("soundexfr", new StandardSQLFunction("util.soundex_fr", StandardBasicTypes.STRING)); registerFunction("jarowinkler", new StandardSQLFunction("util.jaro_winkler", StandardBasicTypes.DOUBLE)); } } |
Puis nous pouvons utiliser les fonctions à travers des prédicats JPA. L’exemple SQL précédent peut s’écrire de la manière suivante :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
import javax.persistence.*; import javax.persistence.criteria.*; // Initialisation EntityManager em = [...]; CriteriaBuilder cBuilder = em.getCriteriaBuilder(); CriteriaQuery<Reclamation> query = cBuilder.createQuery(Reclamation.class); Root<Reclamation> reclamationFrom = query.from(Reclamation.class); // Construction des autres prédicats Predicate otherPredicates = [...]; // Construction du prédicat de recherche phonétique Expression<String> nomPath = reclamationFrom.join("signalant").get("nom"); ParameterExpression<String> nomprocheExpr = cBuilder.parameter(String.class, "nomproche"); // Soundex Expression<String> soundexDb = cBuilder.function("soundexfr", String.class, nomPath); Expression<String> soundexTest = cBuilder.function("soundexfr", String.class, nomprocheExpr); Predicate soundexPredicate = cBuilder.equal(soundexDb, soundexTest); // Jaro winkler Expression<Double> jaroCall = cBuilder.function("jarowinkler", Double.class, nomPath, nomprocheExpr); Predicate jaroPredicate = cBuilder.greaterThanOrEqualTo(jaroCall, 0.75d); // Soundex OU Jaro winkler Predicate phoneticPredicate = cBuilder.or(soundexPredicate, jaroPredicate); // Construction de la requête query.select(reclamationFrom).where(cBuilder.and(otherPredicates, phoneticPredicate)); TypedQuery<Reclamation> typedQuery = em.createQuery(query); typedQuery.setParameter("nomproche", "dupont"); // Exécution de la requête List<Reclamation> reclamations = typedQuery.getResultList(); |
# Pour continuer
La mise en place de ces mécanismes de recherche phonétique dans un projet métier nous a permis d’améliorer la qualité des données saisies très simplement en les valorisant. De plus, l’assistant a une vocation pédagogique. Les opérateurs sont plus vigilants lorsqu’ils saisissent les noms de famille car les erreurs sont mises en avant. Pour finir, l’assistant facilite l’apprentissage de l’anticipation des erreurs qui reviennent régulièrement, avec l’habitude.
Il ne reste plus qu’à imaginer les cas d’utilisations de ces algorithmes dans vos applications !
1 Pingback