Tout juste un an après l’édition 2018, La DevCon 2019 s’est tenue à Édimbourg du 29 au 31 janvier 2019. C’est le rendez-vous attendu par toute la communauté Alfresco pour faire le point sur les dernières avancées de l’éditeur et de ses partenaires et percevoir les orientations de la plateforme dans les prochaines versions. Atol Conseils et Développements a participé avec quatre de ces collaborateurs aux deux journées de conférences et vous propose une synthèse des présentations qui ont retenu notre attention et les axes de développement de la plateforme Alfresco.
Et pour commencer ce programme intense, la keynote de John Newton, CTO et fondateur d’Alfresco, nous rappelle le positionnement de son produit au cœur de la transformation digitale. Il défini cinq axes stratégiques autour desquels s’inscrit le développement d’Alfresco : prioriser la digitalisation des processus/workflow, intégrer les opérations d’infogérance dans le cloud, mettre en oeuvre des traitements à base d’intelligence artificielle, donner les moyens aux utilisateurs au travers d’interfaces puissantes et enfin, accélérer les phases de déploiement. C’est autour de ces différents axes qu’il introduit la roadmap de la plateforme, en présentant les fonctionnalités présentes, à venir et dans un futur un peu plus lointain voire hypothétique de la Digital Business Platform.
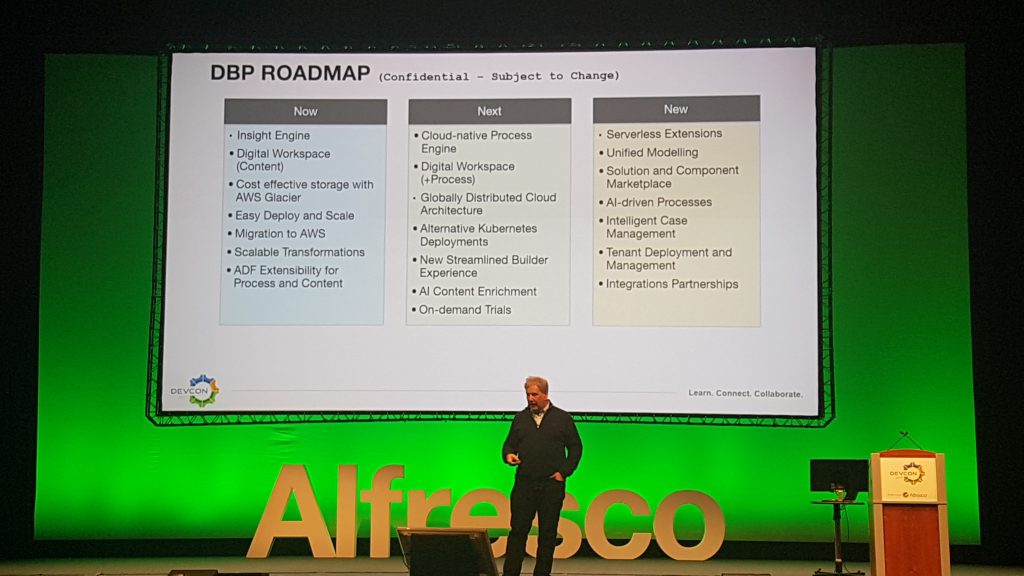
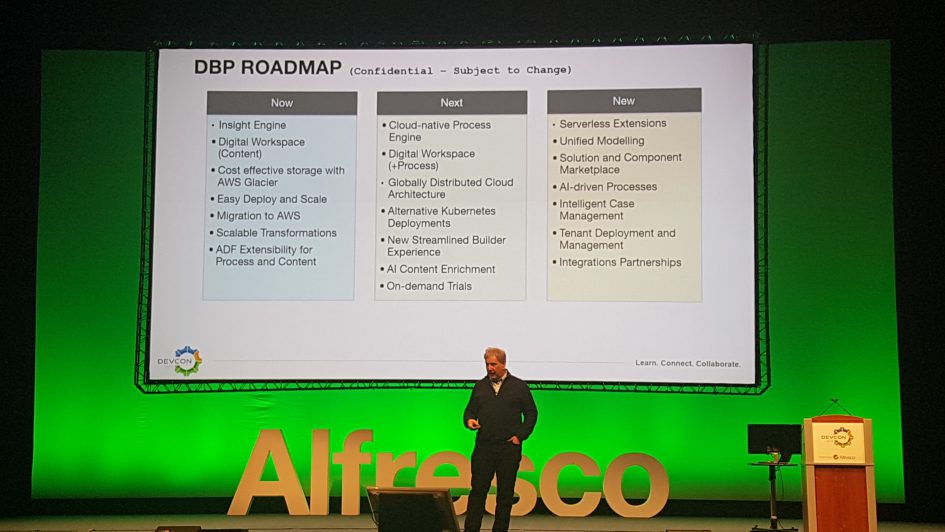
# Roadmap
Les dernières fonctionnalités de la plateforme mises en avant sont :
- Moteur de workflow Activiti Cloud
- Alfresco Process Services (APS) 1.10 (version Entreprise uniquement)
- Déploiement dans le cloud : conteneurs Docker, Kubernetes, architecture micro-services
- Alfresco Transformation Services (ATS) (version Entreprise uniquement) : montée en charge des services différenciés de transformation
- Alfresco Identity Service 1.0 : SSO, OAuth2, SAML2
- SDK 4.0 (et 3.1) : nouvelle version de l’outil pour le développement d’extensions sur Alfresco utilisant Docker
- ADF bien sûr : Angular 7 et capacités d’extension de l’interface par défaut
- réorganisation de la documentation et des pages communautaires autour de l’Alfresco Builder Network
- Alfresco Modeling Application (AMA), une application de modélisation de processus en ADF
- Alfresco Search Services avec Insight Engine (version Entreprise uniquement) : support de requêtes SQL sur le moteur de recherche
- Alfresco Digital Workspace (ADW) (version Entreprise uniquement) pour la gestion de documents
- Desktop Sync pour Alfresco Governance Services (AGS) (version Entreprise uniquement)
- Intégration avec Glacier d’Amazon Web Services (AWS) : en fonction du cycle de vie des documents et l’archivage
- Gestion de processus hors ligne en mobilité (Application iOS uniquement)
En ce qui concerne les évolutions à venir, sans aucune échéance fixée :
- Application de modélisation de formulaires et de processus avancés (version Entreprise uniquement)
- Alfresco Digital Workspace (ADW) (version Entreprise uniquement) avec la gestion de workflows
- Alfresco Identity Services (AIS) avec capacité d’audit avancée (version Entreprise uniquement)
- ADF toujours : meilleur support d’Activiti 7 et APS, accessibilité et amélioration du mécanisme d’extension
- Capacité à développer des extensions pour exécuter des traitements en dehors de l’application Alfresco “Out-of-Process” : à travers des évènements et le bus d’événements Event Gateway
- Serverless extensions
- Alfresco Search Services avec Insight Engine (version Entreprise uniquement) : amélioration de la montée en charge et support d’outils BI
- Intégration d’outils d’enrichissement de contenu à base d’intelligence artificielle : AWS Comprehend, rekognition, Textract…
- Processus intelligents (aide à la décision) à base d’intelligence artificielle
- Amélioration de l’édition Microsoft Office : hors-ligne et directement depuis la suite bureautique
- Alfresco Digital Workspace (ADW) (version Entreprise uniquement) pour Alfresco Governance Services (AGS) : éléments d’interface en ADF pour l’archivage et le records management
- Amélioration des fonctionnalités d’archivage dans Alfresco Governance Services
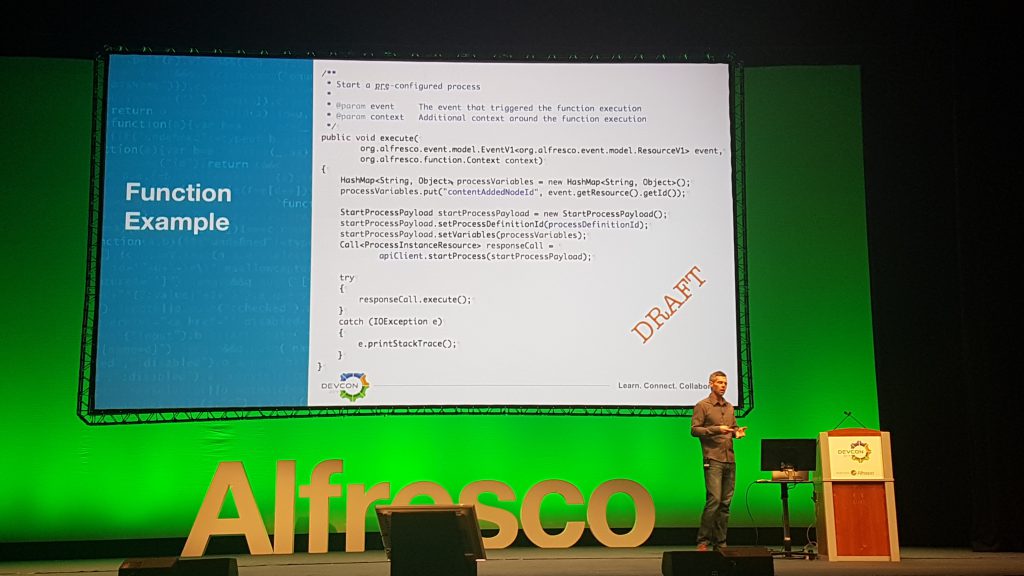
Parmi les actions qui découlent directement des axes stratégiques il y a le fait de rendre l’expérience pour les développeurs de la plateforme la plus étoffée possible et c’est ce qu’on retrouve dans la présentation sur l’Alfresco DBP Builder Experience. Ray Gauss présente des éléments qui vont permettre de développer des fonctionnalités en dehors du coeur Alfresco en se basant sur le bus d’événements : une librairie Java permettant d’interroger l’API Alfresco à la manière du projet alfresco-js-api en TypeScript utilisé par ADF. De plus, l’Event Gateway va pouvoir interroger une base de services ; c’est en définitive les prémices d’une architecture FaaS (Function as a Service) ou Serverless. Il sera ainsi possible de définir des triggers capables par exemple de déclencher un workflow sur la base de la réception d’un certain type d’événement.
# Application Development Framework (ADF)
ADF est un composant essentiel de la plateforme digitale Alfresco “Alfresco Digital Business Platform” (Alfresco DBP) et l’éditeur ne conçoit pas sa plateforme sans ce framework pour concevoir une interface ergonomique à son moteur de GED. Il était donc à prévoir que beaucoup de conférences portent sur le sujet ADF sous différentes formes : son architecture, les évolutions techniques, mais aussi des cas pratiques, des projets en cours de développement avec différents besoins. Nous vous en disons davantage dans l’article dédié à ADF 3.0. L’interface Share reste toujours présente dans la solution et demeure l’interface par défaut de la version communautaire, la version entreprise bénéficiant de l’interface ADW basée sur ADF.
# Architecture
La version 6.0 sortie en juin 2018 était la première étape de séparation des différents services que contient la plateforme Alfresco. La prochaine version 6.1 qui est attendue dans les prochaines semaines continue sur cette lancée en proposant de nouveaux services découplés qui peuvent passer à l’échelle indépendamment et qui ne nécessitent plus de faire des modifications au coeur même d’Alfresco.
Ce type de transformation fait souvent référence au passage à une architecture micro-services. Alfresco préfère parler de services de taille raisonnable en opposition à micro pour rappeler que le but n’est pas d’obtenir les services les plus petits possibles mais de séparer les composants qui peuvent monter en charge indépendamment pour obtenir de meilleurs performances et au final rendre une meilleure expérience globale aux utilisateurs finaux.
Les changements qui nous intéressent le plus concernent l’entrepôt documentaire, dénommé Alfresco Content Services, qui sont finalement assez nombreux avec la version ACS 6.1. D’abord, l’entrepôt va mettre à disposition des métriques sur son utilisation via micrometer (version entreprise uniquement) permettant une supervision avec Prometheus et l’affichage des tableaux de bord dans Grafana. Les indicateurs exposés concernent l’usage de l’API REST, l’accès à la base de données et les performances de la JVM.
Ensuite, la majeure partie des changements provient de l’ajout d’un agent (ou bus) de messages dans l’architecture. En effet, les principales applications de l’Alfresco Digital Business Platform telles qu’ACS, APS et Activiti produisent des évènements bruts (ou internes) qui sont envoyés à l’agent de messages (Message Broker). Ces messages peuvent ensuite être consolidés pour former des évènements publics (ou externes) au format JSON. Le fonctionnement est basé sur un composant Apache ActiveMQ ou dans une infrastructure Amazon Web Services sur AmazonMQ. Il propose des souscriptions sur des files d’évènements JMS.
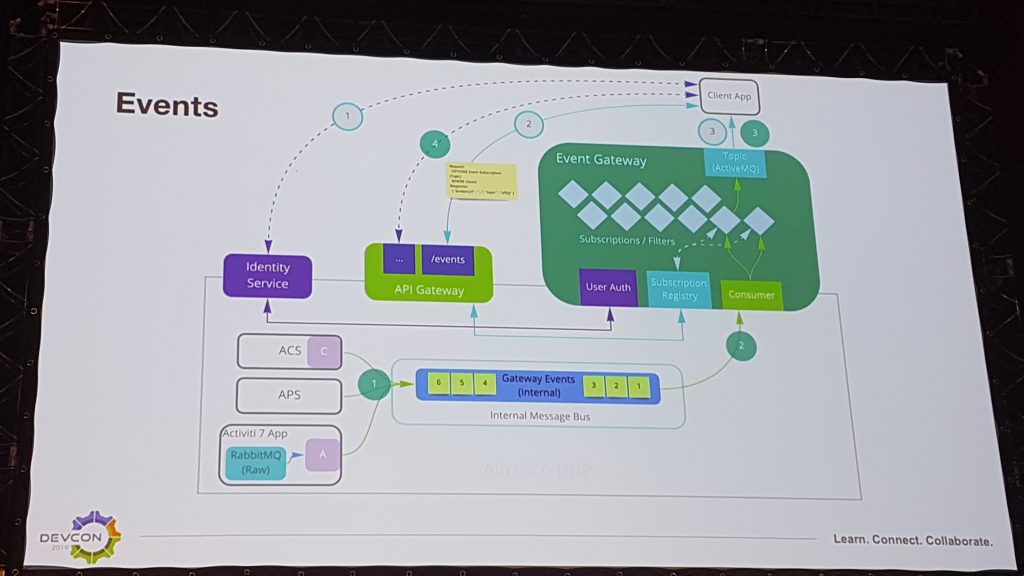
Du côté des applications qui produisent les événements bruts, il n’y a pas à ce stade de gestion de transactions distribuées : les messages sont collectés durant la transaction et une fois celle-ci commitée en base de données alors les données sont envoyées au bus via un TransactionAwareEventProducer. Par exemple, les événements bruts suivants sont produits par ACS : CONTENTPUT, NODEADDED, NODEREMOVED, NODECHECKIN, AUTHADDEDTOGROUP, etc. et par Activiti : PROCESS_CREATED, PROCESS_COMPLETED, TASK_ASSIGNED, TASK_CANCELLED, etc.
Cette architecture était déjà requise pour la mise en oeuvre du Desktop Sync mais devient désormais nécessaire au fonctionnement d’ACS à partir de la version 6.1.
Enfin, la gestion des transformations a été complètement retravaillée. Tout d’abord leur exécution a été systématiquement rendu asynchrone et passe par le bus d’évènements décrit précédemment via le nouveau Rendition Service 2. Ensuite, toutes les transformations elles-mêmes ont été transférées en dehors du processus Alfresco. En effet, l’extraction du texte contenu dans les documents, notamment pour l’indexation Solr, était principalement réalisée par le process Alfresco lui-même (via Apache Tika). De plus, les transformations d’images, de documents bureautiques et de PDF (ImageMagick, LibreOffice, Pdf-renderer), étaient exécutées sur la même machine et la gestion de ces traitements était assurée directement par le Thumbnail Service ou le Rendition Service d’Alfresco. De ce fait et jusqu’à maintenant, si les transformations étaient le facteur limitant de l’architecture il fallait obligatoirement ajouter un nouveau noeud au cluster Alfresco.
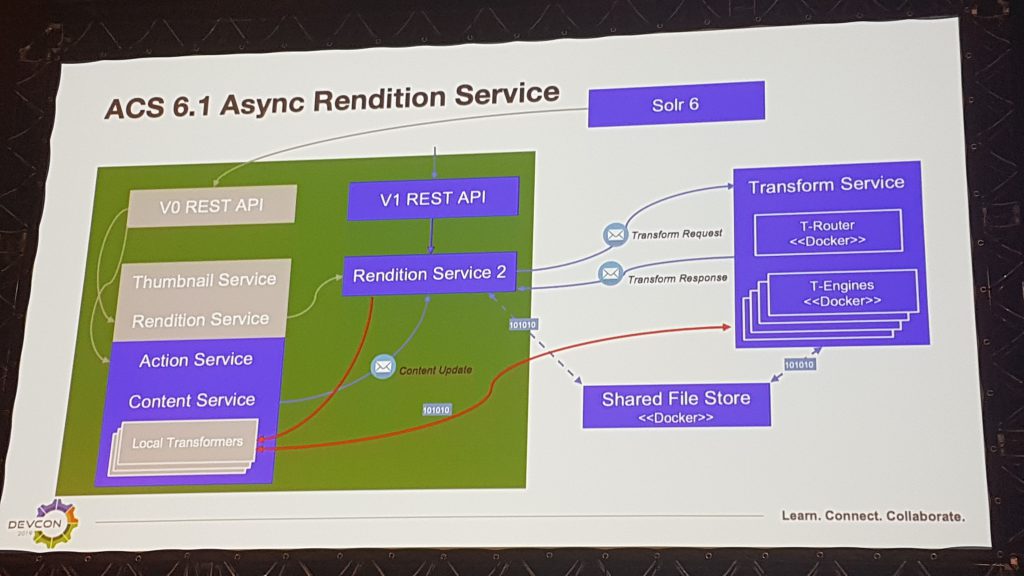
Désormais tous les types de transformation sont séparés dans des moteurs dédiés et pilotés par un processus Spring Boot qui peuvent monter en charge indépendamment. En amont, un routeur permet de dispatcher les événements reçus sur ces différents moteurs. L’ensemble est packagé dans des conteneurs Docker qui peuvent être déployés à la demande et supervisés par Prometheus, via des métriques micrometer.
Il existe également un point de stockage partagé entre tous ces composants afin d’entreposer les sources et les résultats des transformations. En effet, ce ne sont que les ordres de transformation et des pointeurs de fichiers qui sont envoyés dans les messages, les contenus eux ne sont pas transmis dans les flux.
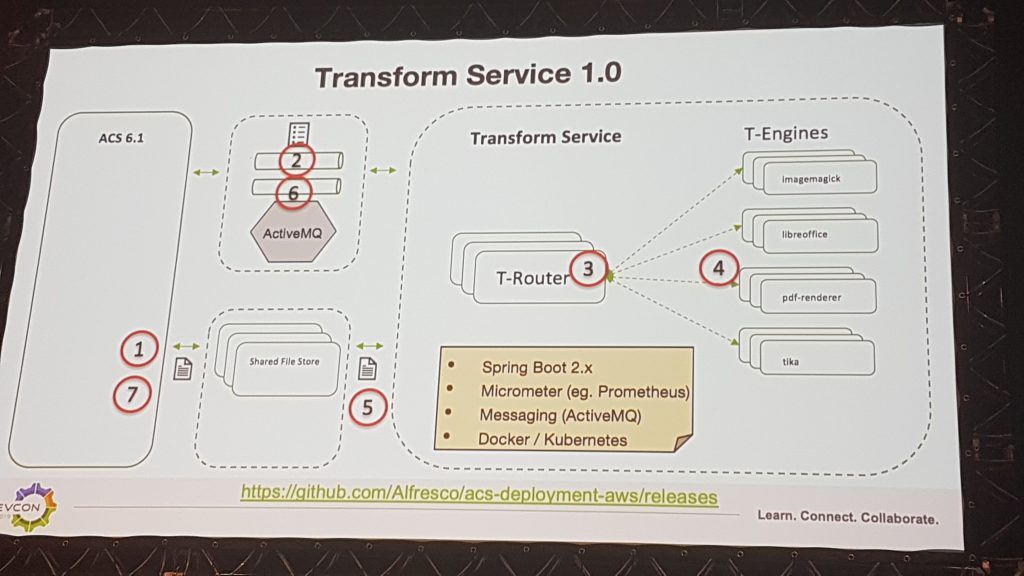
Ces composants sont regroupés sous le nom d’Alfresco Transform Service 1.0. Des évolutions sont d’ores et déjà identifiés sur cette architecture comme la capacité d’ajouter un agent de messages entre le routeur et les moteurs pour rendre davantage asynchrone l’architecture ou la possibilité de changer de technologie de stockage partagée entre tous ces composants. En outre, Alfresco prévoit la possibilité de configurer d’autres moteurs de transformations, notamment des services managés dans le cloud à base d’intelligence artificielle ou la capacité d’ajouter son propre moteur ou service.
Dans la mouvance micro-services initiée par Alfresco mais tant que l’éditeur ne proposait pas de solution de son côté, Jeff Potts nous a présenté une façon de faire permettant de réaliser des développements spécifiques qui interagissent avec le fonctionnement d’Alfresco tout en s’exécutant dans un processus à part. En effet, l’approche traditionnelle pour répondre à ce besoin était de développer des règles et des actions, des comportements voire des webscripts personnalisés, mais toutes ces solutions nécessitent d’effectuer des développements dans le coeur Alfresco.

Le fonctionnement proposé est similaire à celui basé sur l’agent de messages Apache ActiveMQ : Alfresco est étendu pour générer des événements génériques dès lors qu’une action se produit sur un noeud et ceux-ci sont envoyés pour être dispatchés par Apache Kafka vers des applications capables de les traiter. Les caractéristiques de ce type de composant dans l’architecture permettent :
- d’écouter les évènements natifs d’Alfresco
- de filtrer les éléments qui ont un intérêt
- de récupérer des données supplémentaires auprès d’Alfresco à la demande
- d’effectuer les développements spécifiques souhaités en dehors du process Alfresco sans avoir besoin de connaissances avancées sur la solution Alfresco elle-même
- de ne pas dégrader les performances d’Alfresco en réduisant la quantité de code exécuté par le processus Alfresco
- de pouvoir ajouter autant d’applications supplémentaires que de besoin sans modifier Alfresco
- d’utiliser dans les applications des frameworks ou langages différents de ceux de l’entrepôt (pas seulement limité à Java et JavaScript)
Francesco Corti, product manager chez Alfresco, a présenté Alfresco Identity Service (AIS), le service d’authentification unique pour tous les services (ACS, APS, …) du DBP (Digital Business Platform).
Après un bref rappel sur le principe d’authentification, il a évoqué qu’actuellement ACS (Alfresco Content Service) et APS (Alfresco Process Service) gèrent l’authentification de manière indépendante. Cela signifie que l’authentification auprès d’un service, par exemple ACS, ne donne accès qu’à ce service.
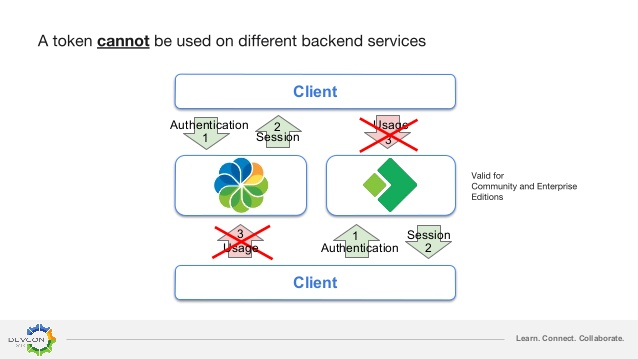
La gestion de l’authentification proposée par AIS crée une session unique qui permet d’utiliser l’ensemble des services d’Alfresco DBP.
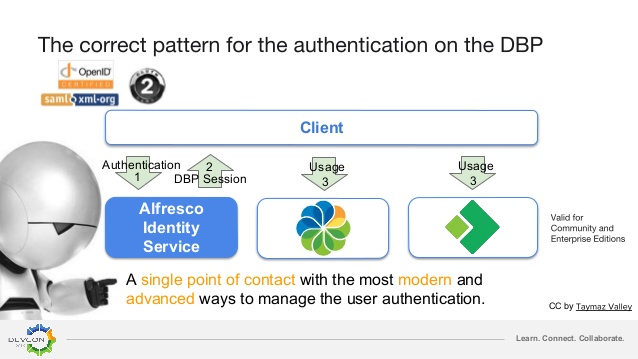
AIS est basé sur le gestionnaire d’identité Keycloak qui utilise des jetons JWT (JSON Web Token) pour matérialiser les sessions des utilisateurs. De plus, l’utilisation de Keycloak permet de tirer parti de protocoles standardisés comme OpenID Connect, OAuth 2.0 et SAML 2.0.
AIS 1.0 n’apporte pas encore de nouvelles fonctionnalités à Keycloak mais il devrait y en avoir dans les prochaines versions, notamment la gestion des utilisateurs et des groupes ainsi que celle de la chaîne d’authentification devrait être reprise d’ACS. A plus long terme, la gestion des permissions pourrait être déléguée à AIS également. Alfresco précise par contre que Share ne devrait pas être compatible avec AIS. En effet, ce n’est pas le cas avec ACS 6.1 mais l’activité sur le ticket SHA-2241 montre que le sujet n’est pas totalement abandonné.
Le sujet de la sécurité est toujours pris très au sérieux par Alfresco. Il existe déjà une extension (en version Entreprise) permettant de chiffrer l’ensemble de l’entrepôt documentaire. Dans ce cas, chaque contenu est chiffré avec une clé symétrique (AES 128 bits) et toutes celles-ci sont elles-mêmes chiffrées avec une clé asymétrique (RSA) et stockées en base de données. Cependant les index et la base de données ne sont pas chiffrés.

Concernant les communications, la stratégie habituelle consiste à sécuriser les échanges seulement entre les clients et le point d’entrée de la plateforme, typiquement un Load Balancer ou un Reverse Proxy avec un certificat TLS (via le protocole HTTPS). Alfresco permet également ce chiffrement dans les requêtes entre l’entrepôt et le moteur de recherche ou la base de données (via le protocole JDBC). Mais l’architecture micro-services présente de nouveaux risques auxquels la plateforme est confrontée et notamment dans toutes les communications inter-services.
Alfresco a donc besoin de chiffrement et d’authentification entre chaque services, mais pas seulement, le changement de paradigme nécessite également des capacités de découverte, de répartition de charge et de supervision. Ces besoins requièrent donc d’étudier la possibilité d’introduire une solution de maillage de services (Service Mesh) dans cette architecture. Alfresco a pour l’instant expérimenté avec la solution Istio qui implémente le modèle d’ambassadeur pour chacun des services. A la manière d’un proxy, ce composant a la responsabilité de la sécurité (mTLS, contrôle d’accès), du routage (règles), de la supervision, ainsi que de la gestion d’erreurs (disjoncteur).
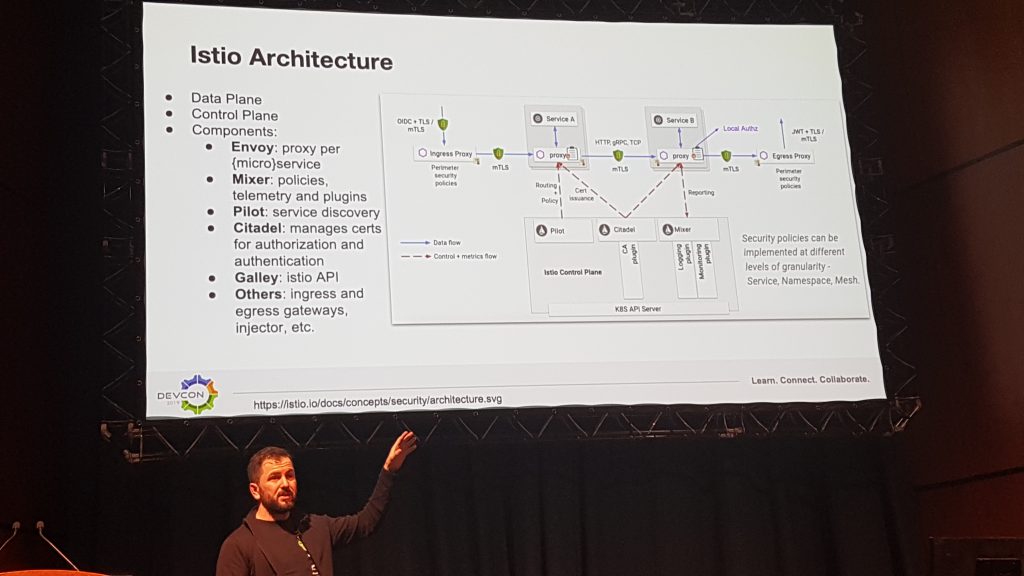
Enfin, du point de vue déploiement et cloud, Alfresco met en avant son architecture modulaire à base de conteneurs Docker. L’image de base inclut Java seulement et est héritée par les services de transformation, de recherche et de bus d’évènement. De plus, une autre image vient ajouter Tomcat et permet de déployer ACS, Share, APS et son interface d’administration.

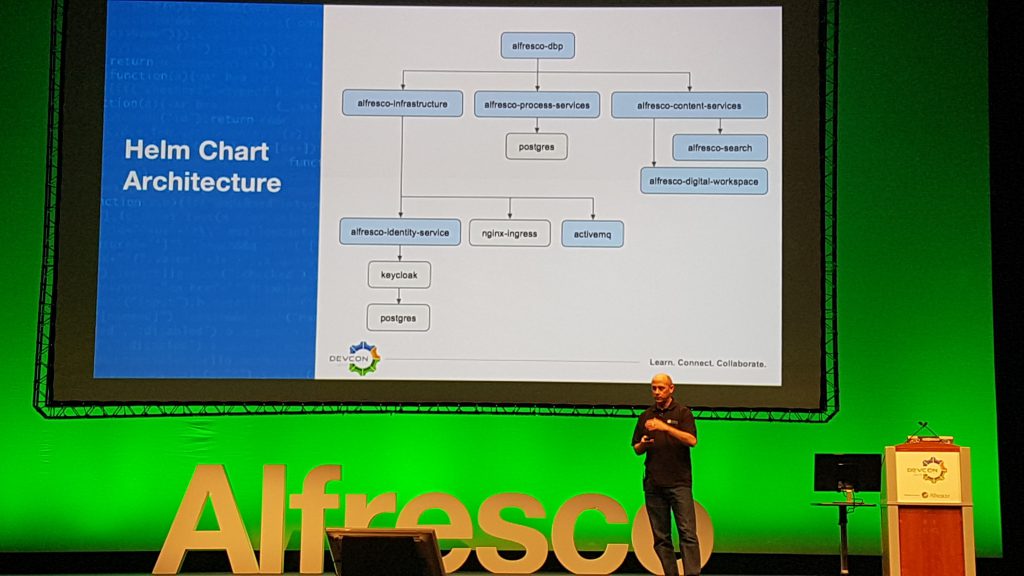
Il existe un modèle Docker Compose pour regrouper tous ces services. Mais cette description ne serait pas complète sans parler de Kubernetes et plus particulièrement d’Helm, son manager capable de déployer les Charts associés. Alfresco fournit les modèles de configurations de déploiement Kubernetes nécessaires au bon fonctionnement de la plateforme qu’il ne reste plus qu’à adapter à la volumétrie de production. Ces configurations supportent une instanciation avec le service EKS d’AWS ou sur une installation locale avec Minikube.
# Bonnes pratiques
Durant cette DevCon, nous avons suivi une série de conférences dédiées aux bonnes pratiques quant au maintien en conditions opérationnelles d’une GED Alfresco.
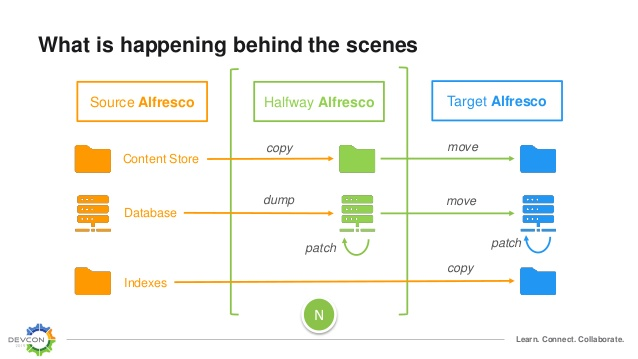
L’une d’entre elles concernait notamment le déroulement de la migration d’Alfresco 4 ou 5 vers Alfresco 6. Il s’agit de bien comprendre ce qui se passe à chaque étape avant de se lancer. La première phase consiste à sauvegarder les données et recenser les personnalisations sur l’environnement source. Le fait d’installer la version cible sur de nouveaux serveurs avec une copie des données est très important car il faut pouvoir relancer les anciens serveurs en cas d’échec de la reprise des données. Il faut toujours commencer par une migration intermédiaire le cas échéant avant de migrer vers la version cible.
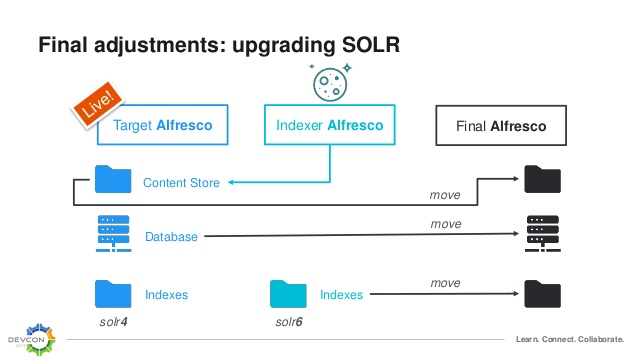
Il est également conseillé de conserver les index solr4 avec la version cible d’Alfresco pendant la construction des nouveaux index solr6 pour limiter l’indisponibilité. En effet, cette réindexation peut prendre beaucoup de temps selon la volumétrie des données stockées dans la GED.
Autre point important à prendre en considération : il faut recenser toutes les fonctionnalités qui ne sont plus d’actualité dans la version cible. De plus, Il faut étudier l’impact de tous ces changements pour pouvoir adapter les personnalisations et mener la conduite du changement avec les utilisateurs. Concernant Alfresco 6, les composants rendus obsolètes sont :
- les binaires d’installation de la plateforme Alfresco
- le support des serveurs d’application JBoss (WildFly), WebSphere et WebLogic
- le système de gestion de base de données d’IBM DB2
- le système d’exploitation Solaris
- le protocole d’accès aux documents CIFS
- le moteur de recherche basé sur Apache Solr 1
- le connecteur Share pour Activiti standalone
- le fonctionnement multi-tenant de l’entrepôt.
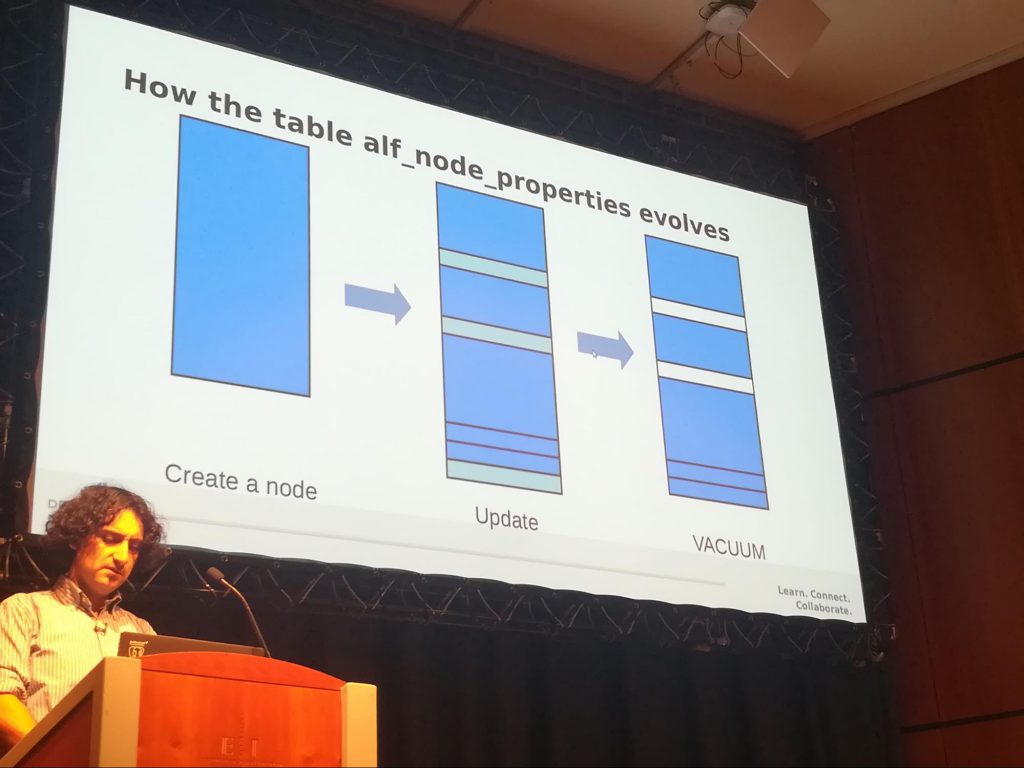
La conférence présentée par Boriss Mejias portait sur des points de configuration de PostgreSQL permettant d’améliorer la stabilité d’Alfresco avec ce Système de Gestion de Base de Donnée (SGBD).
Il proposait de régler les seuils de déclenchement de l’auto-vacuum et de l’analyze pour maintenir des temps de réponse correct de la part du SGBD. Dans la configuration proposée, au bout de 10% de lignes mortes dans les tables on déclenche le vacuum et à 5% de lignes mortes c’est l’analyze que l’on déclenche.
L’intérêt de ce paramétrage a été démontré en rappelant le principe de fonctionnement de PostgreSQL lors d’une suppression ou d’une modification de ligne. Lors de ces opérations en base de données cela crée des lignes mortes, c’est à dire des lignes qui ne sont plus utilisées mais encore présente dans les tables. Plus il y a de lignes mortes avec le temps, plus le temps d’exécution des requêtes est long, il est donc intéressant d’activer l’auto-vacuum et définir des seuils de déclenchement permettant de limiter le nombre de lignes mortes.
Comme la table alf_content_properties est la table la plus sollicitée par l’application, il a été conseillé d’abaisser davantage les seuils juste sur cette table à 1% de lignes mortes pour le déclenchement du vacuum et de l’analyze.
Enfin, la conférence animée par Luis Colorado de Zia Consulting concernait la résolution des problèmes de performance constatés lors de l’utilisation d’Alfresco.
Avec Alfresco les sources possibles des lenteurs peuvent être les suivantes :

Afin de déterminer plus facilement l’origine du problème, il convient de se référer à l’arbre de décision suivant :

En fonction des différents cas, il existe des outils spécifiques pour diagnostiquer le système.
Lorsque la consommation de temps processeur est élevée, les commandes top/htop et sar permettent de voir quels sont les processus qui consomment des ressources, sous Windows il faudra se tourner vers le gestionnaire de tâches. Si c’est Alfresco qui consomme les ressources du processeur, alors des outils comme le Hot Thread ou la jConsole permettent quant à eux de mettre en évidence quels threads de la JVM sont en cause.
Une remarque importante a été faite quant au déploiement d’Alfresco avec Docker : la mesure de consommation CPU n’est pas toujours fiable !
En outre, quand la consommation de CPU est faible mais que l’application est lente malgré tout l’origine du problème est à chercher ailleurs. Cela peut venir de lenteurs au niveau de la base de données ou au niveau du stockage de fichiers.
# Conclusion
Comme vous pouvez le constater, le contenu des conférences était très dense et nous avons eu l’occasion d’évoquer bon nombre de nouvelles technologies. On peut se rendre compte à quelle vitesse la plateforme Alfresco évolue pour être toujours à jour par rapport aux évolutions, que ce soit côté architecture logicielle ou déploiement DevOps.
Les principaux changements en terme d’architecture se concentrent autour de l’agent de message (bus d’événements) et des nouvelles capacités qui sont offertes pour effectuer des traitements asynchrones, à commencer par les transformations. La gestion des identités et la sécurité sont également pris en compte au niveau de chacun des modules tout comme le déploiement qui constituent les enjeux majeurs d’une montée de version vers Alfresco Content Services 6.1. En outre les pré-requis en termes de système ont été mis à jour mais cela ne représente pas un changement radical par rapport à ACS 6.0.
Vous pouvez retrouver l’ensemble des présentations de la DevCon à cette adresse : https://community.alfresco.com/docs/DOC-8095-devcon-2019-speakers-slides
// article co-rédigé par Nicolas Barithel, Matthieu Rollin, Joel Marques et Cindy Piassale
Laisser un commentaire