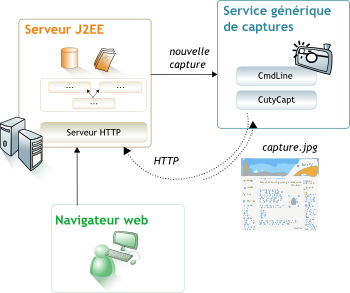
Nous recevons un nombre croissant de demandes de nos clients qui concernent la génération d’un fichier PDF ou d’une image à partir d’une page web issue d’une application métier, un extranet ou encore un intranet. Facile me direz-vous : il suffit d’installer une imprimante PDF telle que PDF Creator ou encore doPDF. Effectivement… Sauf que cette opération nécessite une installation sur le PC de l’utilisateur et que c’est justement ce qu’on essaie d’éviter avec une application web !
Le besoin est réel et il n’existe pas aujourd’hui de solution générique qui fournisse des résultats concluants.
Bien souvent, le réflexe reste de développer un nouveau module pour l’occasion qui traite le cas spécifique de l’impression des informations avec une présentation connue à l’avance.
Partant de ce constat, nous avons décidé de mettre en œuvre une solution générique de capture de pages web côté serveur, avec un fichier produit qui soit le plus fidèle possible au résultat obtenu avec un navigateur classique.
Dans ce billet, je détaille mes pistes de réflexion en exposant ma démarche par étapes et j’expose les résultats obtenus : de l’impression rapide côté client à l’adaptation d’une librairie utilisée côté serveur.

# Piste 1 : Côté client uniquement (javascript)
Pour cette première solution, j’applique un principe tout simple pour imprimer une partie de page : l’isoler du reste !
A partir de l’identifiant de l’élément à imprimer, on duplique le HTML concerné, déjà mis en forme, pour alimenter le corps d’une page qu’on crée à la volée dans une nouvelle iframe. L’iframe prend toute la place disponible dans la fenêtre du navigateur et on lance l’impression sur l’iframe.
Le code source de la fonction javascript disponible ici (le code reste à travailler).
# Test :
Par exemple, sur la page Community du site de Liferay, on souhaite imprimer le contenu de la portlet qui porte le nom « Recent Bloggers ».
En utilisation réelle, on connaît les identifiants des éléments qu’on souhaite imprimer ! Ici, je teste en récupérant l’identifiant du bloc à imprimer, avec les outils de développements de Google Chrome :

Pour lancer l’impression, on se contente d’appeler la fonction javascript écrite au préalable :
printFromId(‘article_14_4467996_1.0’);
Le résultat est conforme à ce qui était attendu :

Lorsque je clique sur le bouton « Imprimer », l’impression est lancée sur le contenu concerné uniquement.
Le résultat est correct, mais dépend du navigateur employé. Je conserve cette solution qui me permettra tout de même de gérer des cas simples.
# Piste 2 : Client vers serveur (javascript, Java)
Cette fois, j’explore une autre piste : l’impression côté serveur en java du HTML transmis par le client.
La raison est triple :
- Le contenu à imprimer n’est pas toujours adressable par URL. Ce cas peut arriver lorsque l’application contient beaucoup de javascript et qu’une « page » n’a pas d’URL (son adresse doit être prévue au départ),
- Les modifications de l’abre DOM sont terminées au moment de la demande : le client s’est chargé des modifications de l’arbre si bien qu’aucune attente ne sera nécessaire côté serveur,
- Le format du fichier rendu est choisi.
Au cours du traitement, deux librairies sont utilisées : HtmlCleaner qui permet d’obtenir du XHTML à partir du HTML et Flying Saucer qui génère un flux PDF à partir du XHTML en utilisant iText.
Le déroulement est le suivant :
- Le client envoie le contenu HTML à imprimer au serveur (éventuellement une partie de page),
- Le serveur prépare le contenu :
- HtmlCleaner « nettoie » en transformant le HTML en XHTML,
- Les URLs sont passées en chemins absolus,
- Les informations d’authentification sont intégrées aux URLs des contenus privés,
- Flying Saucer réalise le rendu final.
Une partie du source java de gestion :
// Récupération de la source HTML
String sourcehtml = (String) request.getParameter(« sourcehtml »);
// Nettoyage du code HTMLHtmlCleaner cleaner = new HtmlCleaner();
TagNode theCleanDoc = cleaner.clean(sourcehtml);
// Création du documentDocument doc = new DomSerializer(cleaner.getProperties()).createDOM(theCleanDoc);
// Gestion des URL du document : URLs relatives/absolues et authentificationmanagePathsInDoc(doc);
// Génération du PDFITextRenderer renderer = new ItextRenderer();
renderer.setDocument(doc, null);
renderer.layout();
OutputStream os = response.getOutputStream();
renderer.createPDF(os);
Même si cette solution 100% java est fonctionnelle, elle n’est pas complètement générique.
En effet, nous nous sommes aperçus en l’utilisant plus concrètement que le rendu était parfois différent de ce qu’on obtient avec un navigateur web classique : nous avons repris certains fichiers CSS. Nous avons également la contrainte du traitement des URLs (méthode managePathsInDoc dans le source). Ce dernier est lié aux gestions des URLs par les navigateurs, ce qui nous amène au second problème : le résultat reste dépendant du navigateur employé au départ.
Pour conclure, cette solution fonctionne mais n’est pas complètement générique.
# Piste 3 : Serveur comme client (Java, WebKit)
# Choix du moteur de rendu WebKit
Finalement, je pars sur une solution qui permettra une plus grande généricité et surtout un rendu plus cohérent : utiliser un des moteurs de rendu des navigateurs les plus répandus.
Je commence par sélectionner le moteur de rendu parmi les plus utilisés :
- Trident par Microsoft Internet Explorer,
- Gecko par Mozilla Firefox,
- WebKit par Safari et Chrome,
- Presto par Opera.
J’exclue Trident car ce n’est pas une solution multi-plateformes et Presto car la licence n’est pas libre. Pour les deux moteurs restants, il existe très peu de librairies java :
- Pour WebKit, le projet JWebPane semble inactif,
- Pour Gecko, JRex permet d’embarquer Gecko dans une application java mais le résultat n’est pas conforme aux attentes.
Au niveau des solutions 100%, ce n’est pas ça. Donc il faudra se pencher sur une autre solution : utiliser une autre librairie.
Continuons sur le sélection du moteur. Finalement, je décide de départager les deux moteurs à un test par équipes (injuste ?!) avec Acid3. Au concours, l’équipe Firefox 3 / Gecko obtient un score de 94/100 alors que Chrome 10 / WebKit atteint 100/100.

Le choix final se porte sur WebKit !
# Qualification de la librairie CutyCapt
Après quelques recherches, je tombe sur un projet qui semble intéressant. Mené par Björn Höhrmann, il répond au nom futé de « CutyCapt ». Sa solution permet de réaliser des captures via la librairie QT qui embarque WebKit dans ses versions récentes.
Je me lance dans une phase de tests.
# Test 1 : CutyCapt avec Windows
Pour l’installation, je récupère l’archive que je décompresse. Puis je lance la commande suivante :
> CutyCapt –url= »http://dev4.mapgears.com/bdga/bdgaWFS-T.html » –out=mydocgis.png –min-width=1024 –min-height=768 –delay=2000 –print-backgrounds=on
Deux secondes après, j’obtiens une image fidèle à ce que je vois avec mon navigateur :

# Test 2 : CutyCapt avec Linux
Je continue le test avec Debian Squeeze. Cette fois, l’installation est plus simple :
# apt-get install cutycapt
Je teste la même commande que sous Windows :
# cutycapt –url= »http://dev4.mapgears.com/bdga/bdgaWFS-T.html » –out= openlayerssample.png –min-width=1024 –min-height=768 –delay=2000 –print-backgrounds=on
# cutycapt: cannot connect to X server
Bon en fait, l’installation n’était pas vraiment plus simple que sous Windows. J’aurais dû anticiper : il me faut un serveur X ! Maintenant, j’ai deux possibilités :
- installer et configurer un « vrai » serveur X,
- utiliser Xvfb (X Virtual Frame Buffer) qui simule un serveur X le temps d’exécution de la requête.
L’objectif de mes tests étant d’avoir une solution fonctionnelle, je laisse de côté cette problématique d’optimisation et j’installe xvfb :
# apt-get install xvfb
Puis je relance la commande légèrement modifiée pour l’occasion :
# xvfb-run –server-args= »-screen 0, 1024x768x24″ cutycapt –url= »http://dev4.mapgears.com/bdga/bdgaWFS-T.html » –out=openlayerssample.png –min-width=1024 –min-height=768 –delay=2000 –print-backgrounds=on
J’obtiens également l’image dans les deux secondes. Et visiblement, le rendu est le même :
J’avoue, l’image est la même dans ce billet, mais je n’allais pas poster deux images au visuel identique !
J’ai la confirmation que c’est une piste intéressante. Je passe à l’étape suivante : réaliser la même chose en java.
# Test 3 : CutyCapt via Java
Je vois deux solutions pour manipuler CutyCapt en java :
- L’utiliser comme une librairie et s’orienter vers JNI (Java Native Interface),
- L’utiliser CutyCapt comme un programme et s’orienter vers une utilisation de la classe ProcessBuilder par exemple.
Je pars sur la seconde possibilité qui est plus rapide à mettre en œuvre. Pour tester l’utilisation de CutyCapt en java, j’écris rapidement le code suivant. Pour changer, je prends une autre URL :
public class BlogTest {
public static void main(String[] args) throws Exception {
String[] commandLine = new String[] { « C:testCutyCapt.exe »,
« –url=http://www.atolcd.com/btn-ll/systeme-dinformation-geographique-web-sig/openlayers/retour-dexperience.html »,
« –out=atolcd_gat.jpg », « –min-width=1024 », « –min-height=768 »,
« –print-backgrounds=on »
};
Process p = new ProcessBuilder(commandLine).start();
p.getErrorStream().close();
p.getInputStream().close();
p.waitFor();
}
}
L’image obtenue est correcte :

# Pour aller plus loin : écriture d’une API Java
Pour aller un peu plus loin, je décide d’écrire une petite API java dont l’objectif reste modeste : il s’agit de simplifier l’utilisation de CutyCapt au sein d’un projet java.
Pour organiser les sources, je procède en deux étapes :
- Abstraire la gestion des lignes de commandes système (ça pourrait servir pour autre chose),
- Ecrire la partie spécifique à CutyCapt en s’appuyant sur les classes écrites précédemment.
Je ne fournis pas de détail sur les deux paquetages. Juste deux diagrammes UML.
Le paquetage java CmdLine :

Le paquetage java CutyCapt :

# Test de l’API
import com.atolcd.labs.cmdline.impl.ExecutableLineParts;
public class BlogTest {
public static void main(String[] args) throws Exception {
// On est sous Linux et on utilise Xvfb (ConfigSingleton est utilisé par ExecFactory)
ConfigSingleton.getInstance(ConfigFactory.createLinuxXvfbConfig());
// On crée la commande en précisant l’URL et le nom de l’image à générer
IExecutable cmd = ExecFactory.createExecutable(
« http://dev.sencha.com/deploy/ChartsDemo/examples/chart/Area.html »,
« test/extjschart.png »);
// On exécute la commande (un test sur result serait souhaitable)
int result = cmd.execute();
}
}
En testant, j’obtiens l’image :

Pour réaliser le même test sous Windows, on remplace simplement l’appel à createLinuxXvfbConfig par un appel à createWindowsConfig.
# Bilan
Les premiers tests sont concluants.
La solution fonctionne sur plusieurs systèmes d’exploitation.
Avec cette solution, nous pouvons générer une image à partir d’une URL. Ainsi, les ressources « imprimables » par ce biais doivent être adressables par URL. Je pense aux applications « full Ajax » qui ont un point d’entrée unique, pour lesquelles il faudra prévoir cet aspect.
En sortie, les images sont fidèles à ce qu’on voit avec un navigateur qui utilise WebKit et les formats sont intéressants : jpg, png, svg, etc.
Nous pouvons différer la capture de manière à ce qu’elle soit réalisée après un délai fixé. Cette attente est nécessaire lorsqu’une application web utilise des requêtes asynchrones dans la mesure où la fin du rendu (quand l’arbre DOM n’est plus modifié) ne coïncide pas avec l’événement « la page est chargée ». Il pourrait-être intéressant d’avoir un moyen fiable (autre qu’un délai) qui permette de s’assurer de la fin réelle du chargement.
Eventuellement, on utilisera l’API dans un thread séparé du thread principal (si possible), de manière à ce que l’exécution principale ne soit pas perturbée par une attente trop longue engendrée par l’utilisation de la librairie.
L’authentification si elle est nécessaire doit être traitée spécifiquement. Par exemple, l’application web implémentera un système d’authentification supplémentaire à base de jeton à durée de vie limitée : génération d’un jeton au départ de la requête et vérification avant prise en charge. On pourra également renforcer la sécurité en filtrant les requêtes en provenance de clients non autorisés (localhost uniquement par exemple).
Pour aller plus loin, on pourrait également approfondir la piste JNI en réalisant un pont avec Webkit avec les axes d’étude suivants :
- utiliser moins de librairies (dans la solution proposée dans ce billet : Java – CutyCapt – QT – WebKit),
- conserver une solution fonctionnelle sur plusieurs systèmes d’exploitation,
- générer un flux plutôt que de passer par une image sur disque,
- améliorer la gestion des webapp asynchrones.
3 octobre 2012 at 15 h 17 min
Merci je viens d’utiliser cutycapt et c’est parfait avec du php !!!
29 décembre 2012 at 9 h 51 min
la solution avec cutycapt (dans mon cas IECapt) c’est nickel pour pentaho CDF 🙂