# Présentation de la stack Elastic « ELK »
Nous profitons de la sortie de la version 6 de la stack Elastic pour présenter la réalisation récente d’un prototype rapide qui s’appuie sur ces outils. La stack Elastic est plus connue sous l’acronyme ELK pour « Elastic », « Logstash », « Kibana ». Ces composants sont publiés en opensource sous licence Apache.
# Elasticsearch
Projet : https://github.com/elastic/elasticsearch
Rôle : « indexer » des données (stockage) et consulter
Interface : API HTTP REST pour :
-
-
alimenter des indexes : créer, mettre à jour, supprimer
-
et pour les interroger
-
Technologie principale : Java
Elasticsearch s’appuie sur des indexes Lucene. Il fournit un moteur de recherche distribué : il est possible de monter des clusters pour répartir la charge ou avoir de la redondance de données.
# Logstash
Projet : https://github.com/elastic/logstash
Rôle : alimenter des données d’une instance Elascticsearch
Interface : configuration du comportement (fichiers texte)
-
initialement prévu pour intégrer des journaux serveurs. Aujourd’hui, il est muni de nombreux plugins :
-
entrée : pour intégrer des informations issues de bases de données, de fichiers, de messages JMS, de messages RabbitMQ, d’un cluster Elasticsearch, etc.
-
filtrage pour transformer les informations : remplacer des valeurs, dupliquer des événements, analyser des dates, supprimer des éléments, etc.
-
sortie : extraire des informations vers un fichier csv, une instance Elasticsearch, email, web service HTTP, etc.
-
-
testé avec le plugin logstash-input-jdbc pour lire directement depuis une base de données
Logstash est un ETL (Extract Transform Load)
Technologies principales : Ruby, Java
# Kibana
Projet : https://github.com/elastic/kibana
Rôle : restituer des données issues d’Elasticsearch et les présenter
Interface : portail utilisateur avec :
-
de la découverte de données : types de données, structuration, contenu
-
des « visualisations » : tableaux, histogramme, courbes, etc.
-
des tableaux de bord : composés de visualisations
Technologies principales : Serveur javascript (NodeJS), Client Angular, React
Remarque : dans sa version actuelle, Kibana n’est pas francisé.
# Exemple de mise en œuvre
# Contexte
Atol Conseils & Développements utilise la stack Elastic dans le cadre du suivi de serveurs hébergés et infogérés. Lorsqu’un incident se produit sur un serveur ou la plateforme, des requêtes spécifiques sur les données indexées au fil de l’eau permettent d’analyser rapidement la situation. La rapidité de création d’un tableau de bord permet également de suivre l’évolution de la situation, le temps de rétablir un comportement normal et de conserver des indicateurs a posteriori.
D’autre part, un prototype a été mis en place dans le cadre d’un projet métier. La suite le décrit dans les grandes lignes.
# Prototype ELK
L’objectif du prototype était d’apporter une réponse concernant la possibilité d’exploiter des données sans connaître leur structuration a priori et en minimisant les contraintes liées à la mise en place.
Le prototype a été réalisé rapidement avec les éléments suivants :
-
Jeu de données issue d’une base métier PostgreSQL : volumétrie d’environ 5 millions d’événements
-
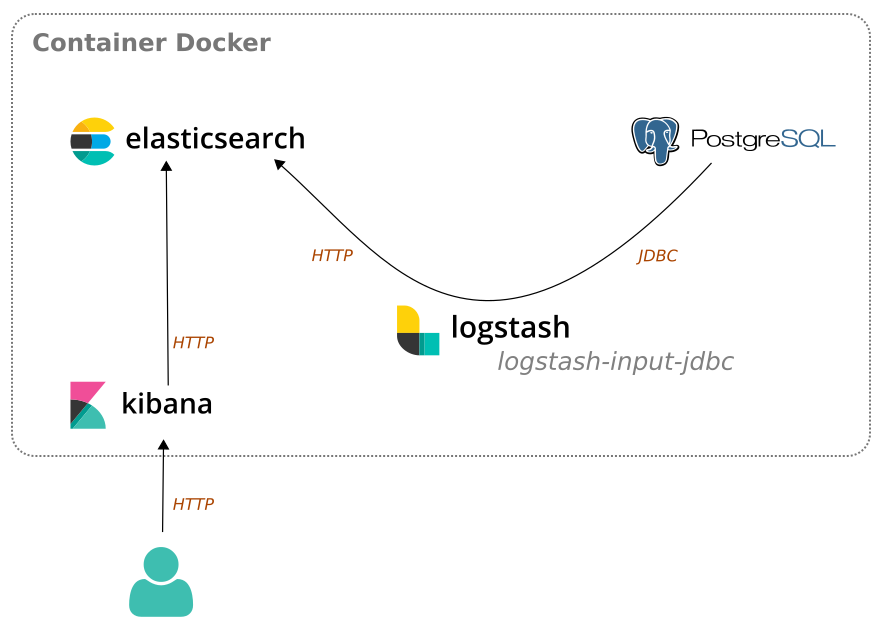
Mise en place d’un container Docker composé de 4 services :
-
PostgreSQL avec une base de données métier
-
Elasticsearch pour indexer les données.
-
Kibana pour le restitution à l’utilisateur
-
Logstash pour l’intégration des données de la base métier vers l’instance Elasticsearch
-
-
Configuration du processus d’intégration des données
-
Création des éléments de restitution
L’objectif est de mettre à disposition des utilisateurs des indicateurs concernant les données métier initiales.
Flux stack Elastic
# Container Docker
Le container a été créé à partir du projet deviantony/docker-elk
Exemple de configuration du container :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 |
version: '2' services: elasticsearch: build: elasticsearch/ volumes: - ./elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml ports: - "9200:9200" - "9300:9300" environment: ES_JAVA_OPTS: "-Xmx256m -Xms256m" networks: - elk logstash: build: logstash/ volumes: - ./logstash/config/logstash.yml:/usr/share/logstash/config/logstash.yml - ./logstash/pipeline:/usr/share/logstash/pipeline - ./logstash/jars:/usr/share/logstash/jars ports: - "5000:5000" environment: LS_JAVA_OPTS: "-Xmx3g -Xms256m" networks: - elk depends_on: - elasticsearch - postgres kibana: build: kibana/ volumes: - ./kibana/config/:/usr/share/kibana/config ports: - "5601:5601" networks: - elk depends_on: - elasticsearch postgres: image: postgres:9.5 ports: - "5433:5432" volumes: - .docker/postgresql:/var/lib/postgresql/data environment: POSTGRES_USER: businessuser POSTGRES_DB: businessusdb POSTGRES_PASSWORD: 5ds4fsdfgfd networks: - elk networks: elk: driver: bridge |
# Logstash : chargement dans Elasticsearch
Le chargement des données dans un index Elasticsearch à partir de la base de données métier PostgreSQL a été réalisé par Logstash muni du plugin logstash-input-jdbc. La requête paramétrée pour le chargement est celle qui permet un archivage des données si bien qu’elle n’a nécessité aucune réflexion supplémentaire. De la même manière, nous n’avons mené aucune réflexion sur la manière dont allaient être exploitées les données à ce stade : dimensions, mesures, etc. telles qu’on doit les prévoir lorsqu’on met en place un cube de données.
Exemple de configuration de la reprise de données dans Logstash :
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
# file: /opt/logstash/pipeline/journalembarque.conf input { jdbc { jdbc_connection_string => "jdbc:postgresql://postgres:5432/businessdb" jdbc_user => "businessuser" jdbc_password => "ds4fsdfgfd" jdbc_validate_connection => true jdbc_driver_library => "/usr/share/logstash/jars/postgresql-9.4-1206-jdbc42.jar" jdbc_driver_class => "org.postgresql.Driver" jdbc_fetch_size => 100 jdbc_page_size => 5000 jdbc_paging_enabled => true statement => "select je.id, je.transmetteur, t.reftrs as transmetteur_reftrs, t.numserie as transmetteur_numserie, je.dhevt, je.dhcreation, je.dureems, je.type, tes.code astype_code, je.sensor, fc.code as sensor_code, je.reflogevent, je.systeme, je.idbadge, je.ack from businessschema.journalembarque je join businessschema.transmetteur t on (t.id=je.transmetteur) join businessschema.typeevenementsite tes on (tes.id=je.type) join businessschema.fonctioncapteur fc on (fc.id=je.sensor)" } } output { elasticsearch { hosts => ["elasticsearch:9200"] index => "journalembarque" document_type => "journalembarque" document_id => "%{id}" } } |
L’intégration peut être rejouée plusieurs fois sans création de doublons. Dans la mesure où nous avons précisé le document_id, un élément de données (notion de document) est inséré ou mis à jour par Elasticsearch (notion d’upsert).
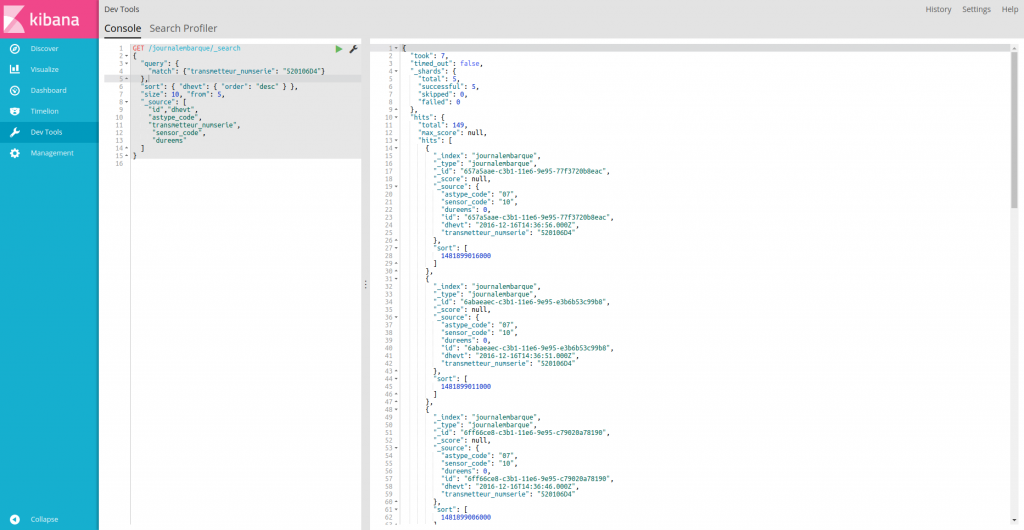
# Elasticsearch : requêtes via les outils pour les développeurs de Kibana
L’onglet ![]() permet de réaliser directement des requêtes via une console.
permet de réaliser directement des requêtes via une console.
L’exemple suivant montre l’interrogation d’une instance Elasticsearch avec :
-
un filtre sur le contenu des données : transmetteur_numserie 520106D4
-
un filtre sur les données restituées : id, dhevt, astype_code, transmetteur_numserie, etc.
-
un tri avec dates d’événement plus récentes en priorité : dhevt desc
-
et de la pagination : size 10, from 5
La requête est à gauche (GET /journalembarque/_search) et la réponse à droite (json) :
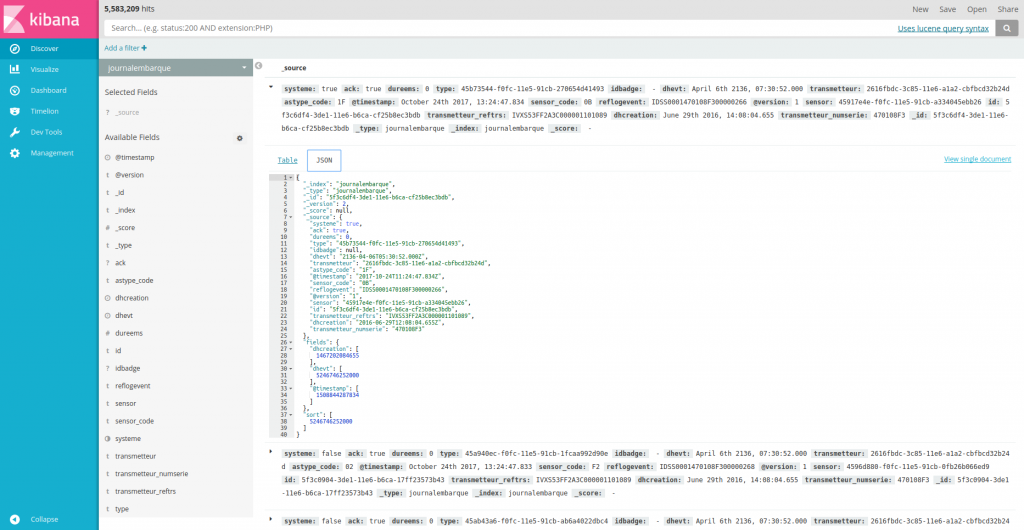
# Kibana : Découverte
L’onglet  permet de parcourir les données sans connaître la structuration des documents à l’avance.
permet de parcourir les données sans connaître la structuration des documents à l’avance.
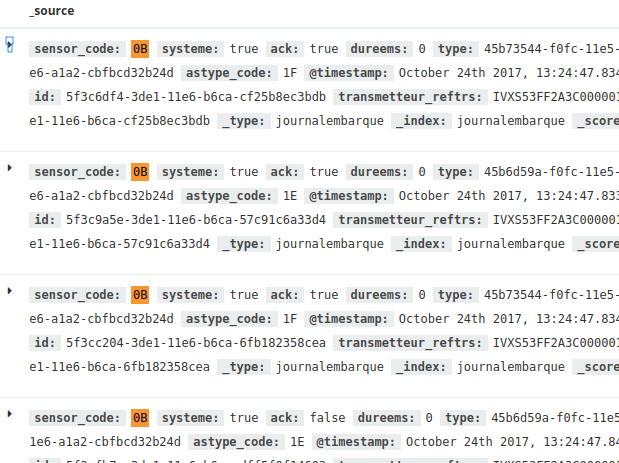
Dans la partie de gauche, on retrouve les champs disponibles. Dans la partie de droite, on retrouve les « lignes » avec pour chacune le contenu présenté en « table » ou en json :
La vue table fournit des filtres :
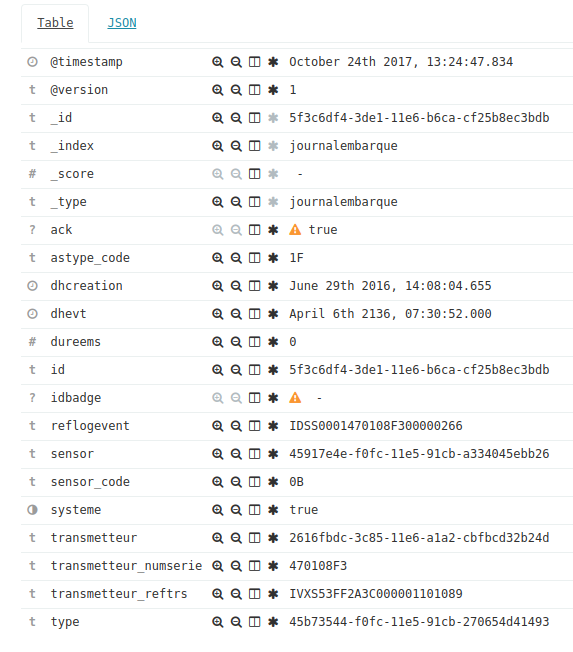
Par exemple en partant du capteur 0B, on obtient les événements du capteur 0B uniquement lorsqu’on clique sur le symbole ![]() sur un événement avec cette valeur :
sur un événement avec cette valeur :
Les actions de filtrage sont les suivantes :
-
 pour filtrer sur une valeur existante
pour filtrer sur une valeur existante -
 pour annuler un filtre
pour annuler un filtre -
 pour basculer la colonne en « table »
pour basculer la colonne en « table » -
 pour filtrer sur la présence du champ
pour filtrer sur la présence du champ
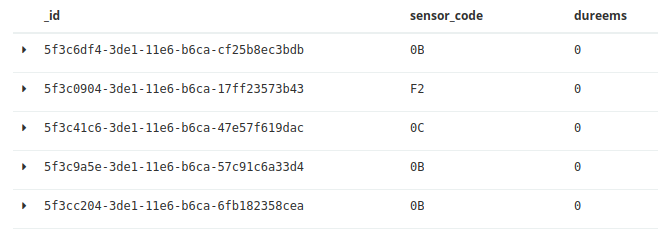
Par exemple en activant la « colonne en table » pour _id, sensor_code et dureems, on se retrouve avec la présentation « tabulaire » suivante :
Remarque :
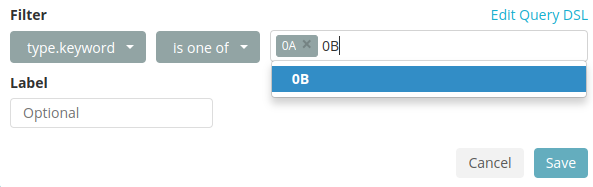
-
Il est possible de paramétrer un filtre via un assistant en cliquant sur
 . Exemple :
. Exemple :
Pour finir, on peut enregistrer son parcours pour le réutiliser ultérieurement ou le partager :

# Kibana : Visualisations
L’onglet ![]() permet de créer des visualisations de données.
permet de créer des visualisations de données.
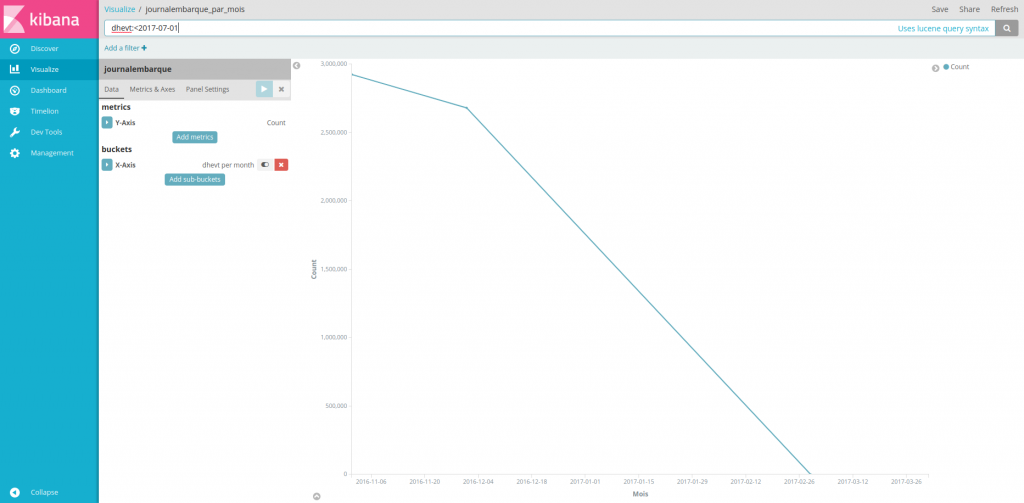
L’exemple suivant montre une courbe avec l’évolution des événements dans le temps (le jeu de données présenté est limité) :
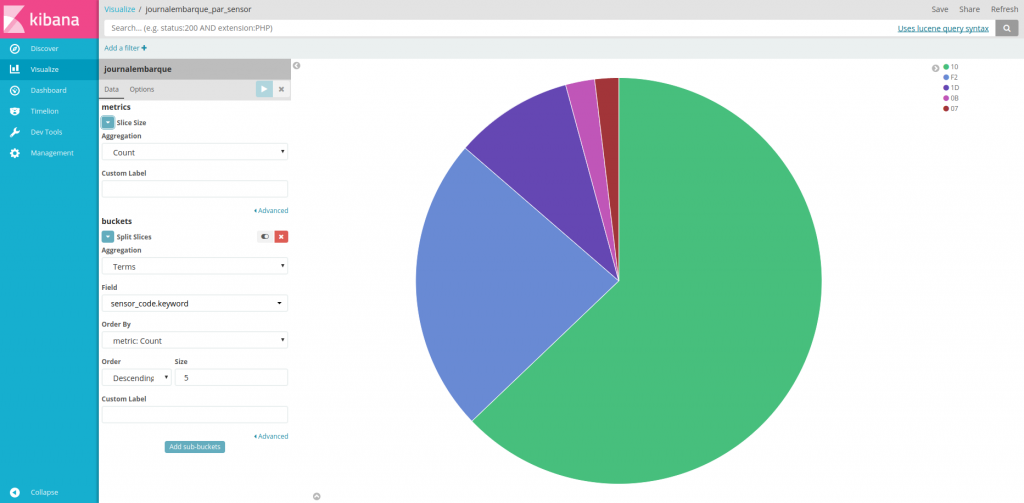
Ci-dessous, le camembert met en avant la répartition des événements des 5 capteurs les plus utilisés :
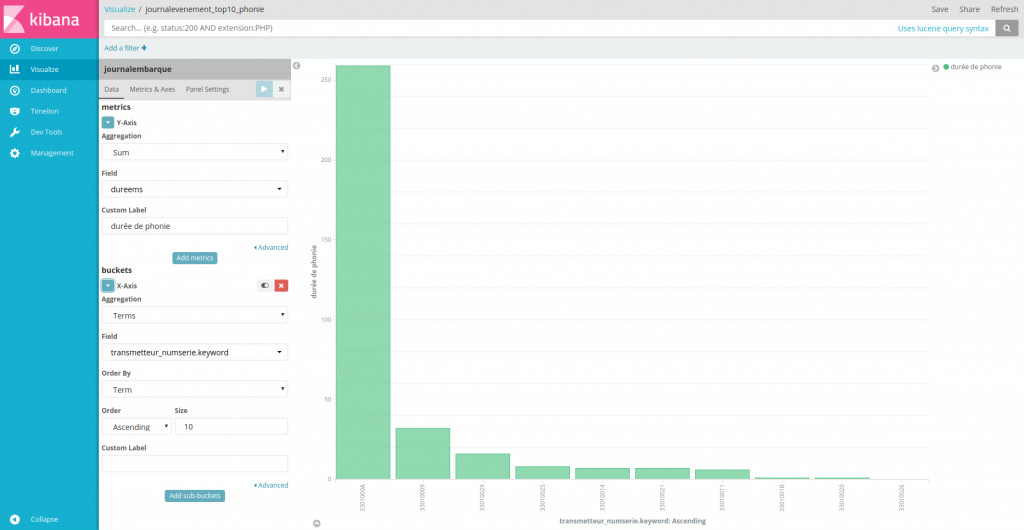
L’histogramme suivant montre les sommes des durées de communication par transmetteurs, trié par volume et limité aux 10 plus gros consommateurs.
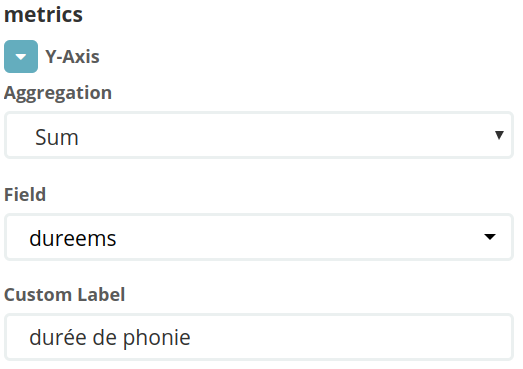
La configuration est réalisée directement dans l’outil :
-
les métriques (count, sum, etc.). Ici, une métrique somme des durées en ms :
-
les regroupements. Ici, un regroupement par numéro de série de transmetteur trié limité à 10 :
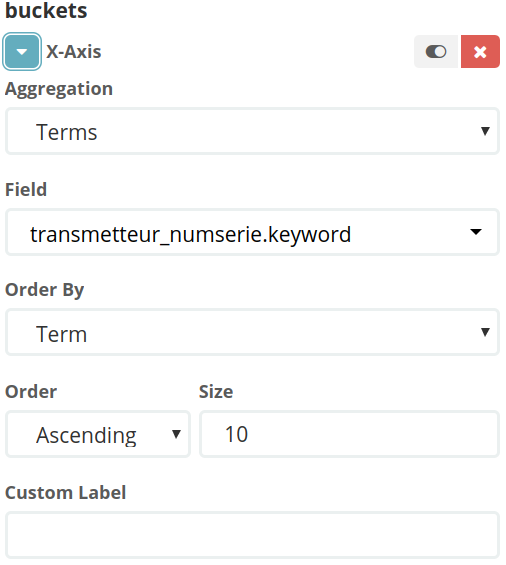
De la même manière que pour la découverte, l’utilisateur peut sauvegarder et partager des visualisations.
# Kibana : Tableaux de bord
L’onglet ![]() permet de créer des tableaux de bords.
permet de créer des tableaux de bords.
Un tableau de bord est composé de visualisations.
Exemple de tableau de bord composé de 6 visualisations :
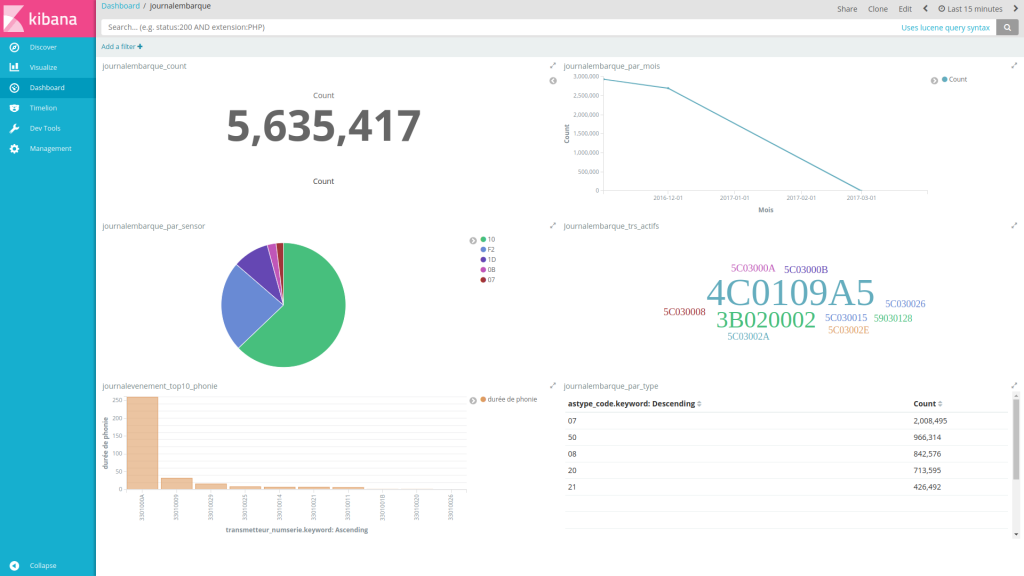
En cliquant sur ![]() , on obtient le code permettant d’intégrer le tableau de bord dans une iframe ou un lien direct (du type http://<SERVEUR_HOTE>:<PORT>/app/kibana#/dashboard/AV9IwydInXPdlHXryKhG?embed=true&_g=()). A partir du lien, on se retrouve avec le même tableau de bord en pleine page.
, on obtient le code permettant d’intégrer le tableau de bord dans une iframe ou un lien direct (du type http://<SERVEUR_HOTE>:<PORT>/app/kibana#/dashboard/AV9IwydInXPdlHXryKhG?embed=true&_g=()). A partir du lien, on se retrouve avec le même tableau de bord en pleine page.
Dans le tableau de bord en question, on peut également appliquer des filtres. Ici, en cliquant sur le capteur « 10 » dans le camembert et sur le type d’événement « 07 » dans le tableau de données, toutes les visualisations composant le tableau de bord sont filtrées sur ces deux critères. On retrouve les filtres en haut, qu’on peut également manipuler : les désactiver, supprimer, etc. L’application d’un filtre est réalisée en quasi temps-réel : les résultats sont disponibles en moins d’une seconde :
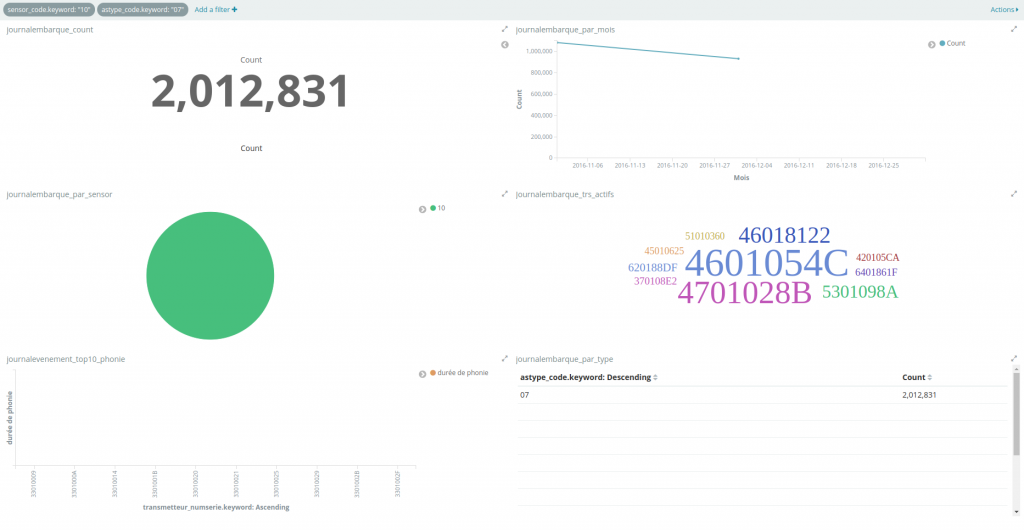
Utilisée telle que décrite, la stack Elastic représente un outil de stockage NoSQL qui permet de faire de l’analyse de données type Big Data de manière intéressante et à moindre coût. De plus la montée en charge est assurée de manière horizontale par la prise en charge en natif de la gestion des clusters Elastic (calculs répartis ou réplication).
Le prototype mis en place rapidement dans une instance Docker montre des temps de réponse satisfaisants (de l’ordre de la seconde).
# Intégration dans une application métier
Nous avons vu l’interface produite à destination d’un profil avancé. Voyons maintenant un exemple d’interface produite au sein d’une application métier pour ayant un profil classique.
Exemple de tableau de bord général avec l’intégration de plusieurs « visualisations » au sein d’un tableau de bord à destination d’un profil métier :
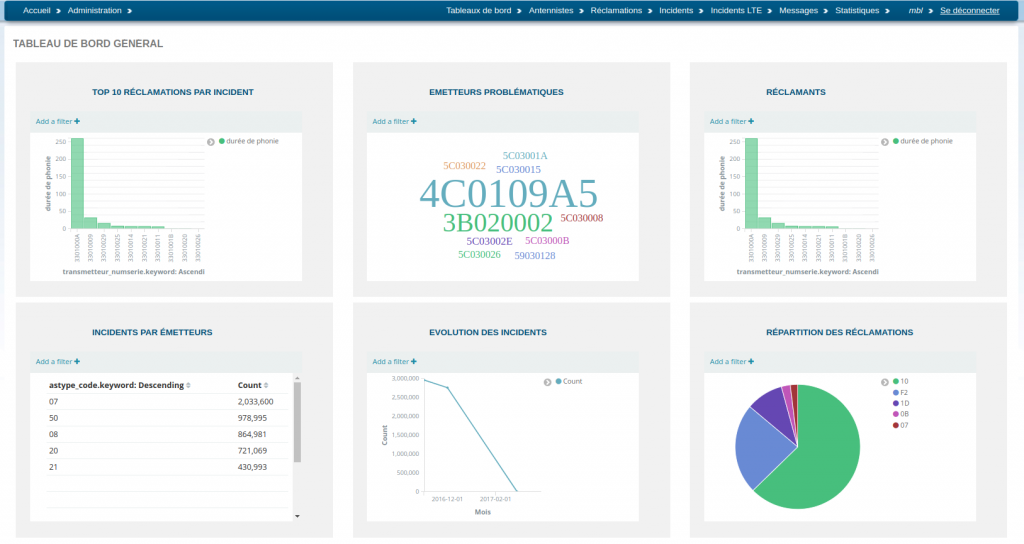
Intégration dans une application métier
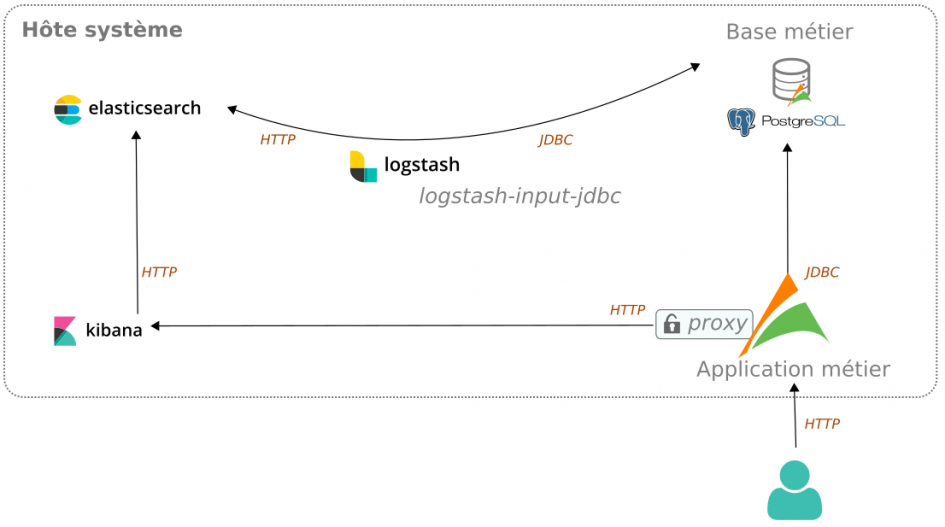
D’un point de vue technique, un proxy est mis en place côté serveur entre le client Kibana et le serveur Elasticsearch. Son rôle est double :
- masquer l’utilisation de la stack Elastic
- sécuriser les accès
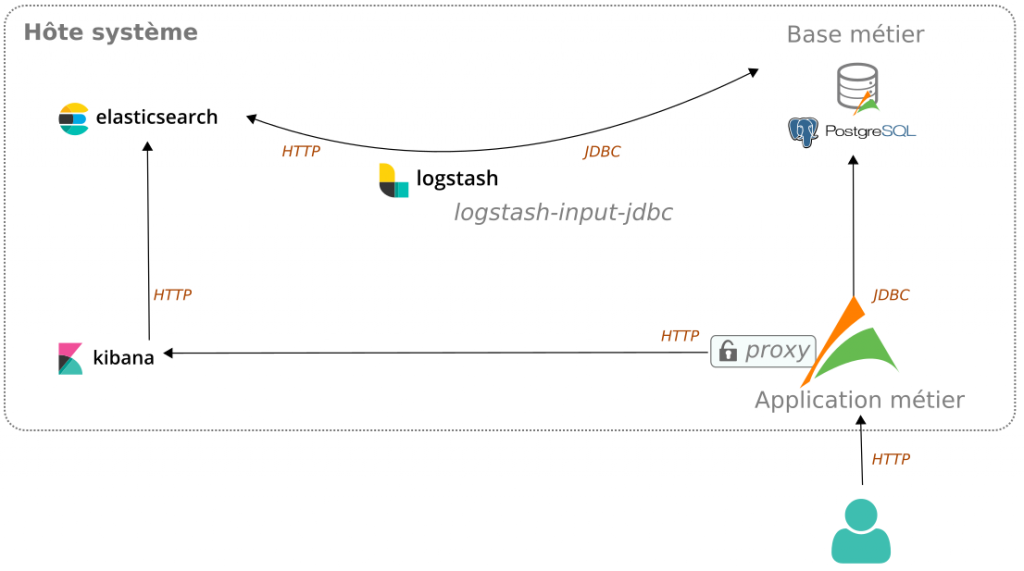
Flux en mode intégré
Nous distinguons deux profils d’utilisateurs :
- L’utilisateur métier « avancé » type administrateur qui paramètre les visualisations Kibana et leur utilisation dans l’application métier (configuration du tableau de bord)
- L’utilisateur métier qui consulte le résultat à travers l’application métier
Ainsi, l’utilisateur métier n’a qu’un seul point d’entrée. Il s’agit de l’application métier.
26 août 2019 at 10 h 06 min
Bonjour merci d’avoir partagé cet article intéressant.
Pouvez-vous nous expliquer comment optimiser l’ingestion des données par Logstash?
Nous avons 1 millions de lignes a charger et c’est trèèèès long plus de 3h.
Si vous pouvez nous dire la configuration du serveur que vous avez utilisé?
Merci beaucoup
6 septembre 2019 at 13 h 32 min
Bonjour Mme,
Je confirme que cet article ne fait pas le focus sur l’optimisation de l’ingestion de données.
La solution à adopter et sa configuration dépendent de nombreux paramètres qu’il convient d’étudier plus précisément : cas d’usage, volume / nombre de lignes, type et serveur de données, environnement d’exécution, etc.
En l’état, vous pouvez vous attarder sur les paramètres jdbc_fetch_size et jdbc_page_size. La documentation officielle mentionne particulièrement le premier paramètre pour le traitement de jeux de données volumineux : https://www.elastic.co/guide/en/logstash/current/plugins-inputs-jdbc.html#_dealing_with_large_result_sets.
Par ailleurs, nous pouvons être amenés à porter notre choix sur d’autres solutions en fonction du cas de figure rencontré. Je vous invite à prendre contact avec nous si vous souhaitez nous exposer votre problématique de manière plus précise.
Merci pour cet échange.